Word Embeddings - Python Automation and Machine Learning for ICs - - An Online Book - |
||||||||
| Python Automation and Machine Learning for ICs http://www.globalsino.com/ICs/ | ||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||
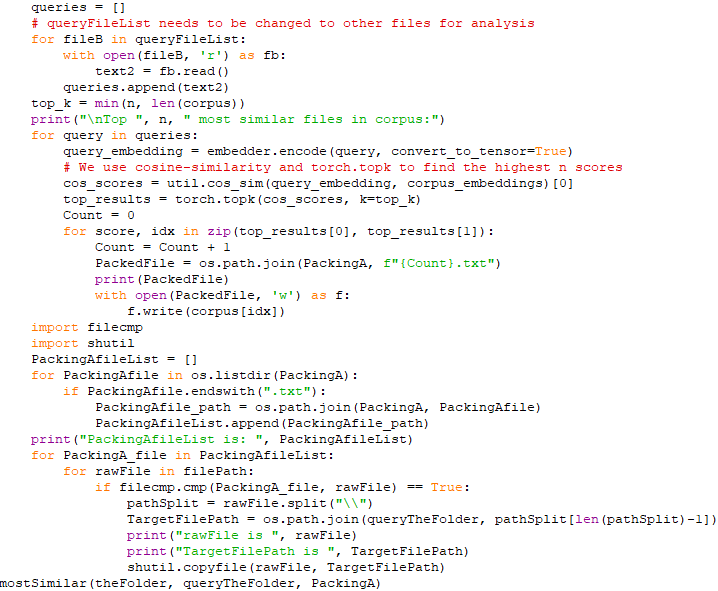
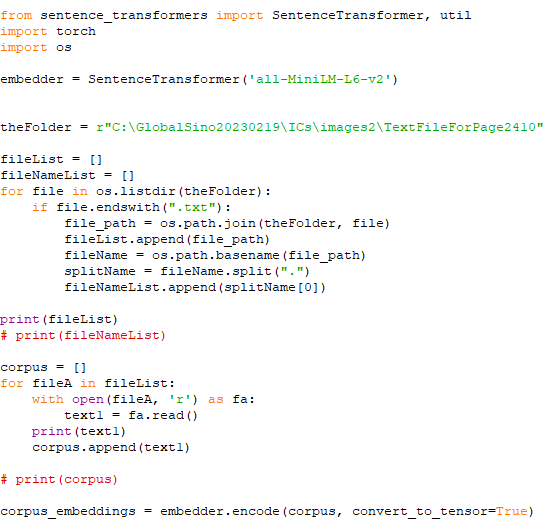
================================================================================= Word embedding algorithms such as Word2vec and GloVe, are key to the state-of-the-art results achieved by neural network models on natural language processing problems like machine translation, so that it is most important technique in Natural Language Processing (NLP). By using word embedding, words can be converted and mapped to vectors of real numbers, so that the meaning of a word in a document can be extracted as well as the relation with other words of that document, semantic and syntactic similarity etc. In natural language processing, we have to make the words understandable for computers. There are several ways to do this, for instance, one hot encoding. In this one hot encoding technique, we create a one hot vector (a vector which has only one 1 value, also others have to be 0) which has a length number of the words we have in our vocab. As an example, for a vocab like {"This","is","Yougui","Liao"}, then each vector for a word will 4D. The vector of "This" is [1,0,0,0], and so on. However, if we compute the distance between "This" and "is", and "is" and "Yougui", we can see the distances are same and thus we could not protect the real relationships between the words. Fortunately, in Word Embeddings, each element of vector is a different number. For instance, for the same vocab like {"This","is","Yougui","Liao"}, their vectors might like this "This" = [1.12,1.42.1,45.1,52]. ============================================ Find the best word similarity with Word2Vec Models/word embeddings: code: ========================= The two scripts specified below belong to the category of "Word Embeddings" algorithms. Word embeddings are a type of word representation in natural language processing that capture the semantic meaning of words by mapping them to continuous vector spaces. In these scripts, sentence embeddings are used, which are an extension of word embeddings to represent entire sentences or phrases as dense vectors. The "sentence_transformers" library utilized in both scripts leverages transformer-based models to generate sentence embeddings. Transformers are deep learning models that have shown significant success in natural language processing tasks and are widely used for tasks like machine translation, sentiment analysis, and text classification. In summary, the scripts use transformer-based models to create word embeddings for sentences, and then they calculate sentence similarities based on these embeddings, making them fall under the "Word Embeddings" category. ============================================ "Word Embeddings" algorithm: Find the most similar text files to the query files in the query folder. (AAA) Code: Note that the Python code above is not a Machine Learning algorithm for Text Analysis, but rather a script that uses a pre-trained Sentence Transformer model to perform text similarity analysis. It finds the most similar texts (similarity tasks) in a corpus to the texts present in a query folder. The code uses the Sentence Transformers library, which provides pre-trained models for generating dense embeddings of sentences. The MiniLM-L6-v2 model is used for text embedding in this case. Here's a breakdown of what the code does:
In summary, the code takes advantage of the Sentence Transformers library, which utilizes pre-trained transformer-based models to create dense embeddings for sentences. It performs a basic text similarity analysis using cosine similarity scores between query embeddings and corpus embeddings to find the most similar texts and then saves them temporarily in a separate folder. A "pre-trained model" refers to a machine learning model that has been trained on a large dataset for a specific task before being used for other related tasks. Pre-training involves exposing the model to vast amounts of data to learn patterns and representations that can be generalized to various downstream tasks. In the case of the code, the "pre-trained model" specifically refers to a language model that has been pre-trained on a vast corpus of text data. This language model is part of the Sentence Transformers library, and it has learned to generate dense embeddings (numerical representations) for sentences in a way that captures the semantic meaning and contextual information of the text. The pre-trained model in the code is called "MiniLM-L6-v2," and it's been trained on a large corpus of text data before being used to generate embeddings for the sentences in the corpus and queries. The advantage of using a pre-trained model is that it can save a significant amount of time and computational resources. Pre-training a language model from scratch on a massive text corpus can be a computationally expensive process, but once the model is trained, it can be used for various downstream tasks like text classification, text similarity analysis, question-answering, and more. By using a pre-trained model like "MiniLM-L6-v2," the Sentence Transformers library can quickly convert text into meaningful numerical embeddings, which can then be used for similarity analysis in the provided code. This approach is much more efficient and practical than training a new model for each specific text analysis task. The use of pre-trained models has become a widespread and popular approach in various fields of natural language processing and machine learning. Here are some references to publications that discuss the applications and advancements of pre-trained models:
These publications highlight the various ways pre-trained models have been utilized, modified, and optimized to achieve state-of-the-art results on a wide range of natural language processing tasks. They have transformed the landscape of NLP research and opened up new possibilities for leveraging large-scale pre-training for downstream applications. The use of pre-trained models in the field of failure analysis of the semiconductor industry was not as prevalent as it was in general natural language processing tasks. However, some references are related to the application of pre-trained models in the semiconductor industry as of 2023:
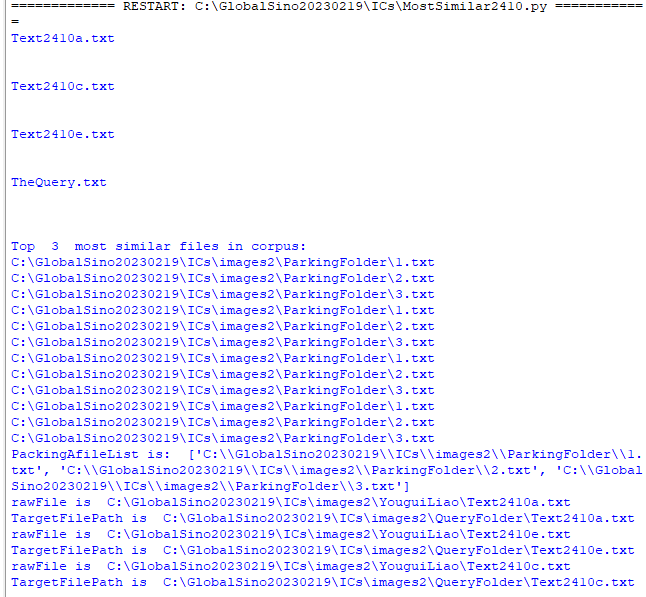
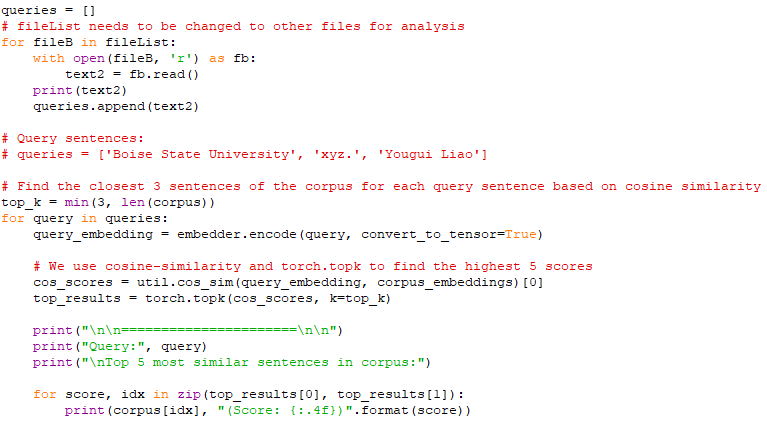
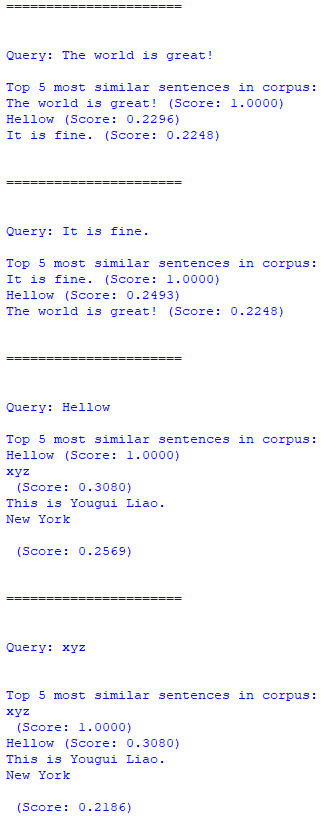
============================================ "Word Embeddings" algorithm: Find the top N most similar texts in the corpus by sentence embeddings with semantic search, which are similar to the target text files. (AAA) Code: The Python code above provided is a basic example of using a Machine Learning algorithm for Text Analysis. Specifically, it uses a pre-trained Sentence Transformer model to encode text into numerical vectors and then performs a text similarity search based on cosine similarity. Here's an overview of the steps:
The main part where the text analysis takes place is the similarity search using cosine similarity. It finds the most similar sentences in the corpus based on the query sentences. Note that the model used in this code is a pre-trained model, and the quality of the text analysis depends on the quality of the pre-trained model and the similarity search approach (cosine similarity in this case). The Sentence Transformer library uses transfer learning from a variety of tasks, including natural language inference and translation, to provide meaningful embeddings. The choice of the model can have a significant impact on the quality of the results. Overall, this code demonstrates a basic example of how to use a Machine Learning model for text analysis with Sentence Transformer for encoding and cosine similarity for similarity search. The following line of code indicates that a pre-trained model is being used:
In this line, the variable embedder is initialized with a Sentence Transformer model. The string argument 'all-MiniLM-L6-v2' represents the name of the pre-trained model that is being used. The SentenceTransformer class is responsible for loading the specified model and creating an instance of the model, which can be used for encoding text into numerical vectors. Pre-trained models are models that have been trained on large amounts of data and learned to represent the meaning and context of natural language. By using such pre-trained models, one can take advantage of the knowledge and features learned during the pre-training phase and use them for specific downstream tasks, such as text analysis, without the need to train a model from scratch. In this code, the model 'all-MiniLM-L6-v2' is a specific pre-trained model from the Sentence Transformer library, and it has the capability to encode text into meaningful numerical embeddings. explain the general concepts behind a typical transformer-based language model like MiniLM, which might give you an idea of how 'all-MiniLM-L6-v2' could potentially work.
Note that the 'sentence-transformers/all-MiniLM-L6-v2' is trained as a variant of the MiniLM model, a smaller and more efficient version of larger transformer models (LLMs) like BERT. ============================================
|
||||||||
| ================================================================================= | ||||||||
|
|
||||||||