=================================================================================
Predictive modeling is a process used in data analytics and statistics to create a mathematical or computational model that can make predictions or forecasts about future events or outcomes based on historical data and patterns. It involves the use of various statistical, mathematical, and machine learning techniques to analyze data, identify patterns, and build models that can be used to make predictions about future events or trends.
Here are the key steps involved in predictive modeling:
-
Data Collection: The first step is to gather relevant data that includes historical information about the phenomenon you want to predict. This data can come from various sources, such as databases, sensors, surveys, or online sources.
-
Data Preprocessing: This step involves cleaning and preparing the data for analysis. It may include tasks like handling missing values, removing outliers, and transforming the data to make it suitable for modeling.
-
Feature Selection/Engineering: Identifying the most relevant variables (features) for the predictive model is crucial. Feature selection involves choosing the most important variables, while feature engineering may involve creating new variables based on existing ones to improve model performance.
-
Model Selection: Choose an appropriate predictive modeling technique based on the nature of the data and the problem you are trying to solve. Common modeling techniques include linear regression, decision trees, random forests, support vector machines, neural networks, and more.
-
Model Training: Using historical data, the selected model is trained to learn the relationships and patterns within the data. The model adjusts its parameters to minimize the difference between its predictions and the actual outcomes in the training data.
-
Model Evaluation: After training, the model's performance is evaluated using a separate dataset that it hasn't seen before (validation or test dataset). Common evaluation metrics include accuracy, precision, recall, F1-score, mean squared error, and others, depending on the nature of the problem (classification or regression).
-
Hyperparameter Tuning: Fine-tune the model's hyperparameters to optimize its performance. Hyperparameters are settings that are not learned from the data but affect how the model learns.
-
Deployment: Once the model performs well on the evaluation dataset, it can be deployed in a real-world setting to make predictions on new, unseen data.
-
Monitoring and Maintenance: Continuous monitoring and maintenance of the predictive model are essential to ensure that it remains accurate and relevant over time. Data drift and model degradation can occur as the environment changes.
Predictive modeling is widely used in various fields, including finance, healthcare, marketing, manufacturing, and many others, to make informed decisions, reduce risks, and improve outcomes by leveraging historical data to make predictions about the future.
Figure 4103a shows how supervised learning works. To provide a precise characterization of the supervised learning problem, the objective is to acquire a function h: X → Y from a given training set. This function, denoted as h(x), should excel at predicting the associated value y. Traditionally, this function h is referred to as a "hypothesis" due to historical conventions.
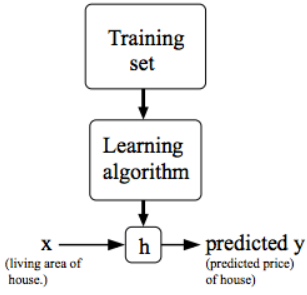
Figure 4103a. Workflow of supervised learning.
============================================
The primary goal of predictive modeling is to make accurate predictions or forecasts about future events or outcomes based on historical data and patterns. The specific objectives and purposes of predictive modeling can vary widely depending on the context and the domain in which it is applied. However, the overarching goal is typically one or more of the following:
-
Prediction: Predictive modeling aims to provide accurate predictions of future events or outcomes. This could involve predicting future sales, customer behavior, stock prices, equipment failures, disease occurrences, weather patterns, and much more. The goal is to leverage historical data to estimate what is likely to happen in the future.
-
Risk Assessment: Predictive models are often used to assess and quantify risks. For example, in finance, predictive modeling can be used to assess credit risk by predicting the likelihood of a borrower defaulting on a loan. In healthcare, it can be used to predict the risk of disease or complications for a patient.
-
Optimization: Predictive modeling can be used to optimize decision-making processes. For instance, in supply chain management, predictive models can help optimize inventory levels to minimize costs while ensuring product availability. In manufacturing, models can optimize production processes for maximum efficiency.
-
Recommendation: In recommendation systems, predictive modeling is used to recommend products, services, content, or actions to users. For example, e-commerce websites use predictive models to recommend products based on a user's past behavior and preferences.
-
Pattern Recognition: Predictive modeling often involves identifying patterns and relationships within data. This can lead to a better understanding of the underlying mechanisms or factors driving certain outcomes, which can be valuable for decision-making and strategy development.
-
Fraud Detection: Predictive models are employed in fraud detection systems to identify potentially fraudulent transactions or activities. These models learn from historical fraud cases to flag suspicious behavior in real-time.
-
Quality Improvement: In manufacturing and process industries, predictive modeling can help improve product quality and reduce defects by identifying factors that contribute to quality issues and suggesting corrective actions.
-
Resource Allocation: Predictive models can assist in the allocation of resources such as budget, personnel, and equipment. For instance, in marketing, predictive modeling can help allocate advertising budgets to channels that are likely to yield the highest return on investment.
-
Preventative Maintenance: In industrial settings, predictive modeling can predict when equipment or machinery is likely to fail. This allows for scheduled maintenance to prevent costly unplanned downtime.
-
Scientific Discovery: In scientific research, predictive modeling can be used to test hypotheses, explore new theories, and make predictions about natural phenomena. For example, climate models predict future climate conditions based on historical climate data and scientific principles.
In essence, the goal of predictive modeling is to leverage data-driven insights to improve decision-making, reduce uncertainty, and enhance outcomes across a wide range of domains and applications. It enables organizations and individuals to anticipate future events, make informed choices, and take proactive measures to achieve their objectives.
============================================
When comparing predictive models, you typically want to assess their performance metrics to determine which model is better at making predictions. Here's how to interpret the metrics you mentioned:
-
R-Squared (R^2): R-squared measures the proportion of the variance in the dependent variable (the variable you're trying to predict) that is explained by the independent variables (the features used in the model). In general, higher values of R-squared indicate a better fit of the model to the data. However, it's not always true that higher R-squared is better because a very high R-squared can indicate overfitting, where the model fits the training data too closely but may not generalize well to new, unseen data. So, it's important to strike a balance and consider the complexity of the model.
- True or False: Lower values of R-squared are better. False. Higher values of R-squared are generally better, but excessively high values can be a sign of overfitting.
- Root Mean Square Error (RMSE) or Root Absolute Squared Error (RASE): RMSE (or RASE) is a measure of the average prediction error in the units of the dependent variable. Lower values of RMSE (or RASE) indicate better model performance because it means that the model's predictions are closer to the actual values. In this case, higher values of RMSE (or RASE) are not better; they indicate worse model performance.
- True or False: Higher values of RASE are better. False. Lower values of RASE are better because they indicate smaller prediction errors.
- Average Absolute Error (AAE): AAE is similar to RMSE but doesn't square the errors. It measures the average absolute difference between the predicted values and the actual values. Like RMSE, lower values of AAE are better because they indicate smaller prediction errors.
- True or False: Higher values of AAE are better. False. Lower values of AAE are better because they indicate smaller prediction errors.
So, to summarize:
- Higher R-squared values are generally better, but extremely high values can indicate overfitting.
- Lower values of both RASE and AAE are better because they indicate smaller prediction errors.
When comparing models, it's essential to consider all these metrics in context, along with other factors like model complexity, interpretability, and the specific goals of your analysis.
============================================
Predictive modeling is indeed used in physical failure analysis in semiconductor wafer analysis. Semiconductor manufacturing is a highly complex process, and ensuring the reliability and quality of semiconductor wafers is critical to the semiconductor industry. Predictive modeling techniques are employed in this domain to predict and prevent failures, improve yield, and optimize manufacturing processes. Here's how predictive modeling is applied in semiconductor wafer analysis:
-
Defect Detection and Classification: Predictive models can be trained to detect and classify defects on semiconductor wafers. These defects can include particles, scratches, and various types of pattern irregularities. Machine learning algorithms, such as convolutional neural networks (CNNs), are often used to analyze images of wafers and identify defects.
-
Process Control: Predictive modeling is used to monitor and control the manufacturing process. By analyzing historical data and sensor readings, models can predict when a manufacturing tool or process is likely to deviate from the desired specifications. This allows for proactive maintenance and adjustments to prevent defects and yield loss.
-
Yield Optimization: Semiconductor manufacturing is highly sensitive to variations in process parameters. Predictive models can be used to optimize process settings to maximize yield and minimize the number of defective wafers produced. These models can consider a wide range of factors, including temperature, pressure, chemical concentrations, and more.
-
Reliability Analysis: Predictive modeling is used to assess the reliability and lifetime of semiconductor devices. Accelerated life testing data and other reliability data can be used to build models that predict failure rates and lifetimes under different conditions. This is critical for industries like automotive and aerospace, where semiconductor reliability is paramount.
-
Anomaly Detection: Predictive modeling can be applied to detect anomalies or unexpected behavior in semiconductor manufacturing processes. Any deviations from expected patterns can be flagged for further investigation, potentially preventing defects or failures.
-
Process Optimization: Models can help optimize the entire semiconductor manufacturing process, from wafer fabrication to packaging. This includes optimizing the allocation of resources, minimizing waste, and reducing energy consumption.
-
Wafer Sorting: Predictive modeling can assist in sorting wafers based on quality and performance characteristics. Wafers can be classified into different bins or categories, ensuring that the most suitable wafers are used for specific applications.
-
Failure Mode and Effects Analysis (FMEA): FMEA is a systematic approach used in semiconductor manufacturing to assess potential failure modes and their consequences. Predictive modeling can be used to simulate and predict the impact of various failure modes on device performance.
In summary, predictive modeling plays a crucial role in semiconductor wafer analysis and manufacturing. By leveraging historical data and applying advanced analytics and machine learning techniques, semiconductor manufacturers can improve yield, enhance reliability, and reduce defects, ultimately leading to higher-quality semiconductor devices and more efficient manufacturing processes.
===========================================
Model validation is a crucial step in predictive modeling, and it serves the primary purpose of assessing how well a machine learning model is likely to perform on new, unseen data. The primary reasons for using model validation to ensure that your model generalizes well to new data are as follows:
-
Avoiding Overfitting: One of the most common challenges in predictive modeling is overfitting. Overfitting occurs when a model learns to fit the training data too closely, capturing noise and random fluctuations instead of the underlying patterns. An overfitted model will perform exceptionally well on the training data but poorly on new, unseen data because it has essentially memorized the training set. Model validation techniques help detect and prevent overfitting by evaluating the model's performance on data it hasn't seen during training.
-
Assessing Generalization Performance: The ultimate goal of predictive modeling is to make accurate predictions on real-world, unseen data. Model validation provides an estimate of how well your model will perform in practice. By using techniques like cross-validation, hold-out validation, or out-of-sample testing, you can simulate how your model will behave when it encounters new data. This helps you gauge whether your model has learned meaningful patterns or is simply memorizing the training data.
-
Hyperparameter Tuning: Model validation is essential for hyperparameter tuning, which involves finding the best set of hyperparameters (e.g., learning rate, number of layers, depth of a decision tree) for your model. You can experiment with different hyperparameter configurations and use validation performance as a guide to select the optimal values. This process helps ensure that your model is well-tuned for generalization.
-
Model Selection: In some cases, you may want to compare multiple algorithms or model architectures to determine which one performs best on your specific task. Model validation enables you to make an informed choice by evaluating the performance of different models on the same validation dataset. Selecting the model that generalizes best is critical for achieving accurate predictions.
-
Detecting Data Issues: Model validation can also help you identify data quality issues or data leakage. Unusual patterns in validation performance may indicate issues with the training data, such as outliers, missing values, or inconsistencies. Detecting and addressing these problems is essential for improving model generalization.
In summary, model validation is a critical step in predictive modeling because it helps you assess and improve your model's ability to generalize to new, unseen data. It serves as a safeguard against overfitting, guides hyperparameter tuning and model selection, and helps you identify potential data issues. Ultimately, using model validation techniques ensures that your machine learning model is more likely to perform well in real-world applications.
==========================================
Sequential API can be used to create a Keras model with TensorFlow (e.g. on Vertex AI platform). Then, the Keras Sequential API and Feature Columns can be used to build deep neural network (DNN). In combination with a trained model, the Keras model can be saved, loaded and deployed, and then the model can be called for making predictions. The primary goal of predictive modeling is to predict what may happen next.
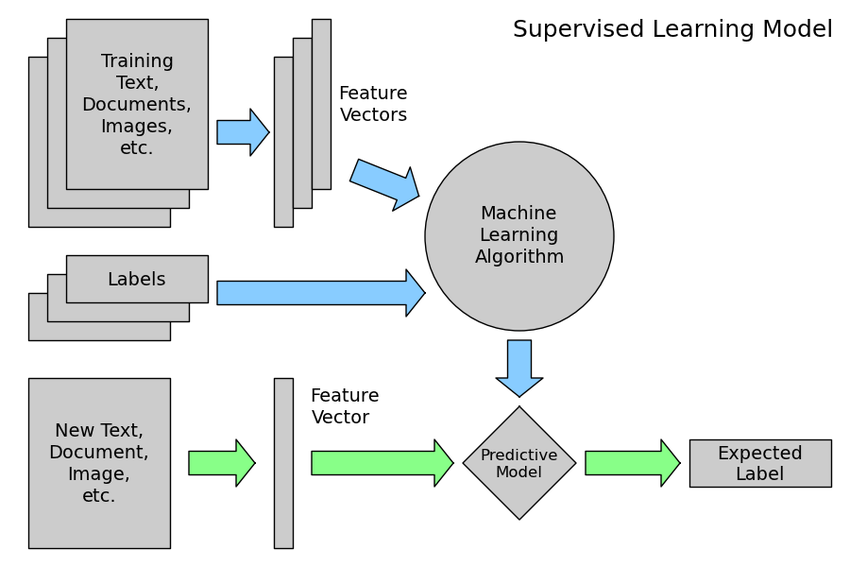
Figure 4103b. Overview of the proposed ML method in the publication. [1] |
Figure 4103c shows simplified overview of a machine learning workflow. The machine learning model is trained on input data gathered from different databases. Once it is trained, it can be applied to make
predictions for other input data.
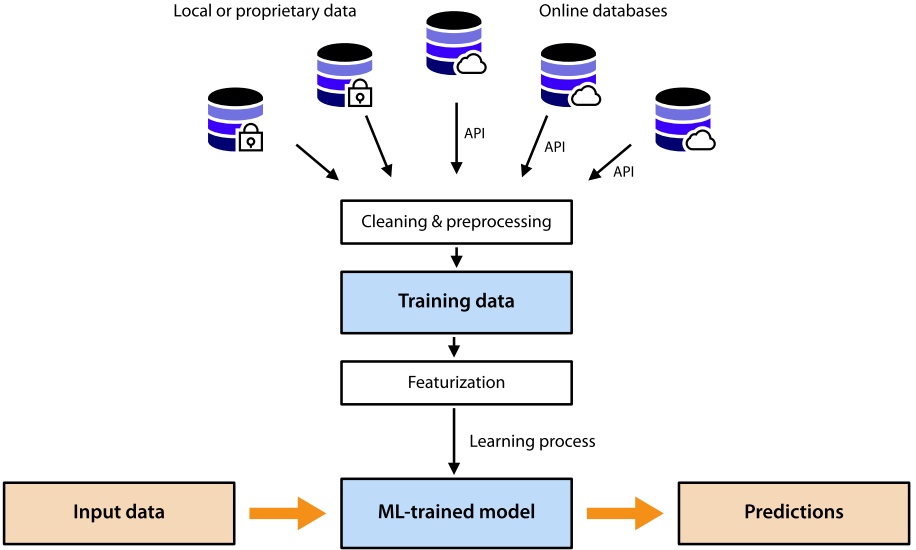
Figure 4103c.
Simplified overview of a machine
learning workflow. [2] |
The predict function in the tf.keras API returns Numpy array(s) of predictions. The reason of why you should hold back data for validation and testing is to make sure that your model generalizes well to new data.
Table 4103. Exmaples of prediction models.
| Prediction model |
Application |
| Decision tree model with scikit-learn |
And fits it with the features and target variable for prediction of house prices (page4036) |
============================================
[1] Dan Ofer, Machine Learning for Protein Function, thesis, 2018.
[2] Siwar Chibani and François-Xavier Coudert, Machine learning approaches for the prediction of materials properties, APL Mater. 8, 080701 (2020); https://doi.org/10.1063/5.0018384.
|