|
||||||||
Clustering of Texts - Python Automation and Machine Learning for ICs - - An Online Book - |
||||||||
| Python Automation and Machine Learning for ICs http://www.globalsino.com/ICs/ | ||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||
================================================================================= Text clustering is the process of grouping similar texts from a set of texts and has several levels of granularity, namely document, paragraph, sentence, or phrase level. Text clustering involves the task of categorizing a collection of texts, aiming to place similar texts within the same cluster while differentiating them from texts in other clusters. Manual text grouping is a labor-intensive process that demands a significant investment of time. Consequently, the integration of machine learning automation becomes imperative. Among the frequently employed techniques for representing textual data, Term Frequency Inverse Document Frequency (TFIDF) stands out. However, TFIDF lacks the ability to consider word position and context within sentences. To address this limitation, the Bidirectional Encoder Representation from Transformers (BERT) model generates text representations that encompass word position and sentence context. On the other hand, diverse methods of feature extraction and normalization are applied to enhance the data representation offered by the BERT model. To evaluate the performance of BERT, different clustering algorithms are employed: k-means clustering, eigenspace-based fuzzy c-means, deep embedded clustering, and improved deep embedded clustering. From a machine learning point of view, text clustering is an unsupervised learning method utilizing unlabeled data [1]. For instance, text data available on the internet generally do not have a label. In fact, various unsupervised learning algorithms have been implemented to perform text clustering. Some examples are k-means clustering (KM) [4], eigenspace-based fuzzy c-means (EFCM) [5], deep embedded clustering (DEC) [6], and improved deep embedded clustering (IDEC) [7]. SentenceTransformers, as shown in Figure 4029, is a framework for state-of-the-art sentence, text and image embeddings in Python.
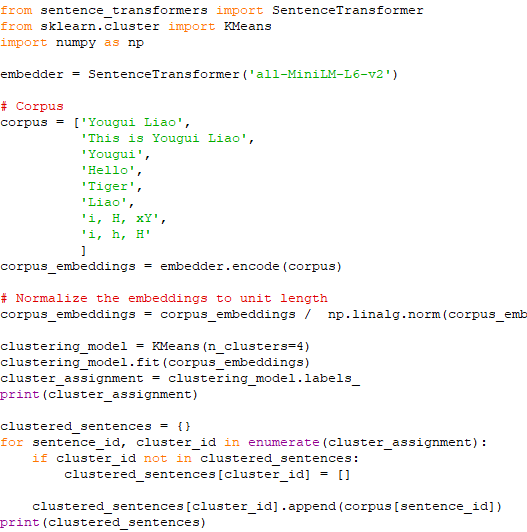
Figure 4029. SentenceTransformers. Text clustering has been applied in many felds such as book organization, corpus summarization, document classifcation [2], and topic detection [3]. ============================================ Clustering of texts. Code: ============================================
[1] Bishop CM. Pattern recognition. Mach Learn. 2006;128:9.
|
||||||||
| ================================================================================= | ||||||||
|
|
||||||||