=================================================================================
Multiple linear regression is a statistical technique used in predictive modeling and data analysis. It extends simple linear regression, which models the relationship between a dependent variable (response) and a single independent variable (predictor), to situations where there are multiple independent variables that may influence the dependent variable. In multiple linear regression, you aim to understand how these multiple predictors collectively affect the response variable.
The multiple linear regression model is represented as:
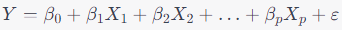 ---------------------------------------------- [4007] ---------------------------------------------- [4007]
Where:
Overall, multiple linear regression is a valuable tool for exploring and modeling relationships between multiple predictor variables and a response variable, allowing for the prediction and interpretation of real-world phenomena.
============================================
Multiple linear regression makes several assumptions about the errors or residuals of the model. These assumptions are important for the validity of the regression analysis and the interpretation of its results. Here are the key assumptions for the errors in multiple linear regression:
-
Linearity: The relationship between the independent variables and the dependent variable is assumed to be linear. This means that changes in the independent variables are associated with constant changes in the dependent variable.
-
Independence: The errors (residuals) should be independent of each other. In other words, the value of the error for one observation should not be influenced by the values of errors for other observations. This assumption is often referred to as the independence of observations or the absence of autocorrelation.
-
Homoscedasticity: The variance of the errors should be constant across all levels of the independent variables. This means that the spread or dispersion of the residuals should not change as you move along the range of the predictors. In practice, you can check for homoscedasticity by plotting the residuals against the predicted values or the independent variables.
-
Normality of Residuals: The errors should be normally distributed. This means that the distribution of the residuals should approximate a normal (Gaussian) distribution. You can assess this assumption by creating a histogram or a Q-Q plot of the residuals and checking for deviations from normality.
-
No Perfect Multicollinearity: The independent variables should not be perfectly correlated with each other. Perfect multicollinearity occurs when one independent variable can be perfectly predicted from another(s), making it impossible to estimate the coefficients uniquely. High multicollinearity (though not perfect) can also be problematic as it can lead to unstable coefficient estimates and difficulties in interpretation.
-
No Endogeneity: The independent variables are assumed to be exogenous, meaning they are not affected by the errors. Endogeneity occurs when there is a bidirectional relationship between the independent variables and the errors, which can bias the coefficient estimates.
-
No Outliers or Influential Observations: Outliers are data points that significantly deviate from the overall pattern of the data. These outliers can have a disproportionate impact on the regression results. Influential observations are data points that have a strong influence on the regression coefficients. Detecting and addressing outliers and influential observations is crucial.
-
No Heteroscedasticity: This is the opposite of the homoscedasticity assumption. Heteroscedasticity refers to a situation where the variance of the errors is not constant across levels of the independent variables. It can lead to inefficient coefficient estimates and incorrect standard errors.
It's important to assess these assumptions when conducting multiple linear regression analysis and take appropriate steps if any of them are violated. Various diagnostic tools and statistical tests are available to check these assumptions and address potential issues in the regression analysis. Failure to address violations of these assumptions can lead to biased and unreliable results.
============================================
|