=================================================================================
Optimization is about choosing the best option from a set of options in machine learning. Optimization in machine learning involves finding the best set of parameters or configurations for a model to improve its performance on a given task. This process often includes minimizing a loss function, which measures the difference between the predicted output and the actual output. Techniques like gradient descent are commonly used for optimization in machine learning to iteratively adjust parameters and reach the optimal solution.
Table 3970a. Various optimization techniques used in machine learning.
| Optimization |
Definition |
Comments |
| Gradient Descent |
A first-order iterative optimization algorithm for finding the minimum of a function. |
|
| Batch gradient descent |
It is an optimization algorithm used in machine learning that updates model parameters by computing the gradients of the entire training dataset, making it computationally expensive but providing a precise direction for convergence. |
|
| Stochastic Gradient Descent (SGD) |
A variant of gradient descent where a random subset of data is used to compute the gradient. |
|
| Mini-Batch Gradient Descent |
A compromise between batch gradient descent and stochastic gradient descent, where updates are made using small batches of data. |
|
| Adam Optimization |
An adaptive optimization algorithm that combines the advantages of both AdaGrad and RMSProp. |
|
| Adagrad |
An adaptive learning rate optimization algorithm that adjusts the learning rates of each parameter individually. |
|
| RMSProp |
An adaptive learning rate optimization algorithm that helps mitigate the diminishing learning rate problem. |
|
| Momentum Optimization |
Introduces momentum to the gradient descent algorithm, helping accelerate convergence. |
|
| L-BFGS (Limited-memory Broyden-Fletcher-Goldfarb-Shanno) |
A quasi-Newton optimization algorithm that uses limited memory. |
|
| Genetic Algorithms |
Optimization algorithms inspired by the process of natural selection. |
|
| Particle Swarm Optimization (PSO) |
An optimization technique inspired by the social behavior of birds and fish. |
|
| Simulated Annealing |
A probabilistic optimization algorithm that mimics the annealing process in metallurgy. |
|
| Bayesian Optimization |
An optimization strategy based on probabilistic models and Bayesian reasoning. |
|
| Blackbox optimization algorithms |
It refers to scenarios where the objective function to be optimized is treated as a "black box," meaning that its internal workings are not explicitly known. The optimizer can only interact with the function by providing input values and observing the corresponding output. |
|
| Local search | It is an optimization algorithm that iteratively explores the neighboring solutions of a current candidate solution, moving towards better solutions in the search space until an optimal or satisfactory solution is found. | |
|---|
| Hill Climbing | Hill climbing is a local search algorithm that starts with an arbitrary solution to a problem and iteratively makes small changes to it, moving towards a higher-value solution. The goal is to find the peak of the solution space, which represents the optimal solution according to the evaluation function. | |
|---|
In machine learning, an optimizer is a crucial component of training a model, particularly in deep learning and neural networks. Optimizers (or called optimization algorithms) is used to minimize loss function. Its primary function is to adjust the model's parameters (such as weights and biases), iteratively during the training process, to minimize a specified loss or error function. The goal is to find the optimal set of parameters that make the model perform well on the given task.
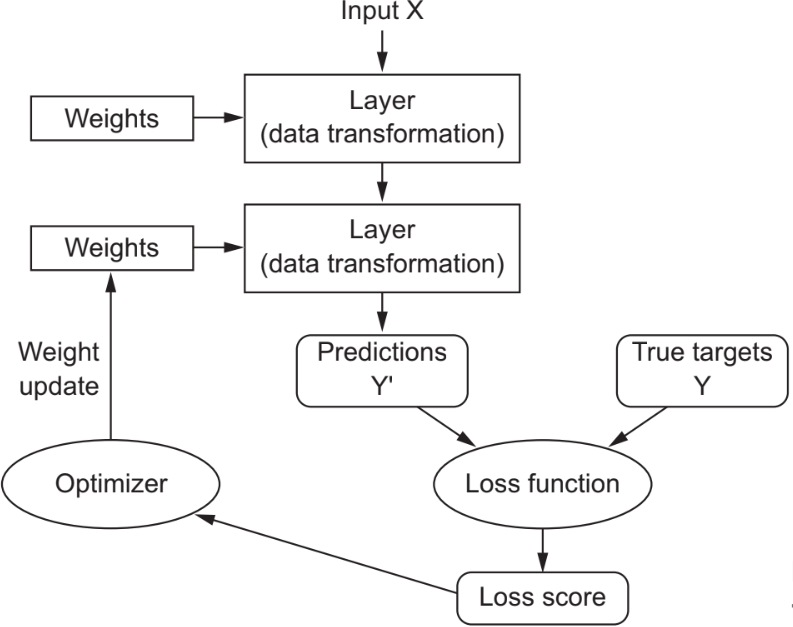
| Figure 3970a. Optimizer to adjust the model's parameters to minimize a specified loss or error function. [1] |
Here are some key points about optimizers in machine learning:
-
Optimization Objective: The primary objective of an optimizer is to minimize a predefined loss function or cost function. This loss function quantifies the error between the model's predictions and the actual target values in the training data.
-
Gradient Descent: Most optimizers are based on gradient descent or its variations. Gradient descent is an iterative optimization algorithm that updates model parameters in the direction that reduces the loss. It computes the gradient of the loss with respect to the model's parameters and then adjusts these parameters in small steps to move towards the minimum of the loss function.
-
Learning Rate: The learning rate is a hyperparameter that controls the step size in each iteration of the optimization process. It determines how much the model's parameters are updated based on the gradient. Setting the appropriate learning rate is critical, as a too small or too large value can lead to slow convergence or overshooting the minimum, respectively.
-
Types of Optimizers: There are various optimizers available, each with its own characteristics and advantages. Some common optimizers include:
- Stochastic Gradient Descent (SGD)
- Mini-Batch Gradient Descent
- Adam (Adaptive Moment Estimation)
- RMSprop (Root Mean Square Propagation)
- Adagrad (Adaptive Gradient Algorithm)
-
Momentum: Some optimizers, like SGD with momentum, incorporate a momentum term to improve convergence speed. Momentum helps the optimizer overcome local minima by allowing it to accumulate past gradients and move with more inertia in certain directions.
-
Convergence: The optimization process continues until a termination condition is met, such as a maximum number of iterations or a certain level of convergence in the loss function. The model's parameters are considered optimized when the loss function reaches a satisfactory minimum.
-
Regularization: Some optimizers can incorporate regularization techniques, like L1 and L2 regularization, to prevent overfitting by penalizing large parameter values.
The choice of optimizer and its hyperparameters can significantly impact the training process and the performance of the machine learning model. Different optimizers may perform better or worse on specific tasks and datasets, so hyperparameter tuning is often required to find the best combination for a given problem.
============================================
[1] Fransois Chollet, Deep Learning with Python, 2018. |