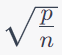Infinite Hypothesis Class - Python for Integrated Circuits - - An Online Book - |
||||||||
| Python for Integrated Circuits http://www.globalsino.com/ICs/ | ||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||
================================================================================= An infinite hypothesis class is a concept often encountered in machine learning and statistics. It refers to a set of potential models or hypotheses that can be used to represent data or make predictions, and this set is infinite in size. In contrast, a "finite hypothesis class" would be a limited set of models or hypotheses to choose from. There are a few key points to know about infinite hypothesis classes:
In practice, dealing with infinite hypothesis classes often involves introducing additional assumptions, regularization, or priors to make the learning problem tractable and avoid overfitting. These techniques help strike a balance between model complexity and generalization to new, unseen data. Bounding the performance of models in an infinite hypothesis class is a complex problem, and it often depends on the specific context, assumptions, and learning framework. Consider the setting of Linear Regression: In linear regression, you have a model like this: Where:
You want to estimate the coefficients based on a training dataset of size . Potential bounds are: i) This is sometimes used to express the trade-off between model complexity (determined by ) and the amount of data (determined by ). When Here's how this bound works::
ii) Rademacher Complexity: Rademacher complexity measures the ability of a class of functions to fit random noise. It's often used in statistical learning theory to bound the generalization error. For a hypothesis class , Rademacher complexity iii) VC Dimension: The Vapnik-Chervonenkis (VC) dimension is a combinatorial measure of the capacity of a hypothesis class to shatter data points. If the VC dimension is , it implies that the class can fit any set of � data points. This dimension can be used to bound the sample complexity. iv) PAC Learning Bounds: In the Probably Approximately Correct (PAC) learning framework, bounds are derived for the number of samples needed to ensure that a learning algorithm produces a good hypothesis with high probability. v) Regularization Terms: In practical machine learning, regularization terms (e.g., L1, L2 regularization) are added to the loss function to bound the complexity of the learned model. These bounds are often problem-specific and are used to guide the choice of model complexity, regularization, and sample size based on the specific characteristics of the data and the learning problem. Assuming H is parameterized by Θ ∈ℝp then, H = {hθθ: ∈ Consider Assuming, 0 ≤ L((x,y), θ) ≤ 1 for every x, y, θ L((x,y), θ) is k-Lipschitz in θ for every x, y. Then, we have theorem, that is, for any θ and θ', the absolute difference of the loss functions can be bounded by K times the L2 norm of the difference between θ and θ': ||L((x,y), θ) - L((x,y), θ')| ≤ K||θ||₂ -------------------------- [3936c] The Lipschitz condition is often desirable in mathematical optimization, machine learning, and other areas for several reasons:
However, whether a specific k value (Lipschitz constant) is considered "very good" or "reasonable" depends on your problem's requirements. Smaller values of k generally imply greater stability and more predictable behavior, but they might also indicate slower convergence or overly conservative generalization. Larger values of k might allow faster convergence but can result in less stable or less robust functions. It's essential to choose a Lipschitz constant (k) that strikes a balance between your optimization or learning objectives and the constraints and stability requirements of your problem. In many cases, the choice of k involves trade-offs and often depends on empirical experimentation to find an appropriate value that works well for the specific task at hand. ============================================
|
||||||||
| ================================================================================= | ||||||||
|
|
||||||||