Threading - Python for Integrated Circuits - - An Online Book - |
||||||||
| Python for Integrated Circuits http://www.globalsino.com/ICs/ | ||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||
================================================================================= Threading in the context of machine learning typically refers to a technique used to parallelize or distribute computations across multiple CPU cores or threads in order to speed up training or inference processes. Threading is particularly useful when dealing with large datasets or complex models that require significant computational resources. In the context of deep learning, neural networks are often trained using gradient-based optimization algorithms like stochastic gradient descent (SGD). These algorithms involve iteratively updating the model's parameters by computing gradients with respect to the loss function. These gradient calculations can be computationally intensive, especially for large models and datasets. Threading can be employed to distribute the computation of these gradients across multiple CPU cores, which can lead to faster training times. It allows multiple threads to work concurrently on different parts of the dataset or even different mini-batches, thus reducing the overall training time. Here's a simplified illustration of how threading can be used in the context of gradient calculation during the training of a neural network:
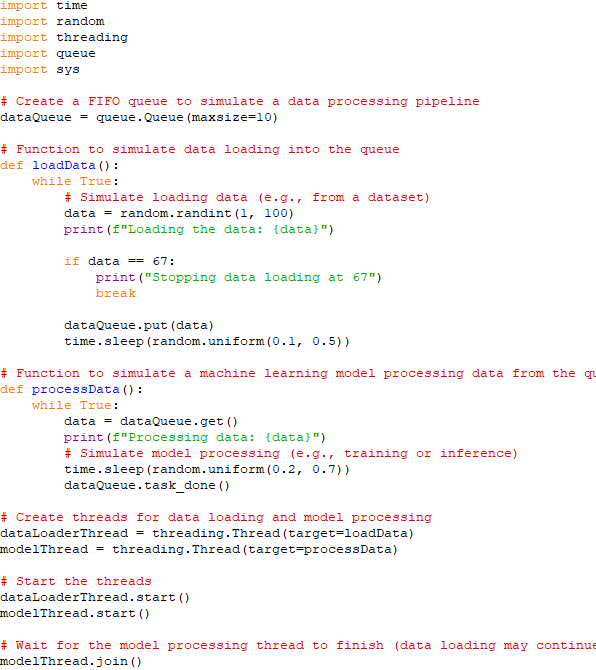
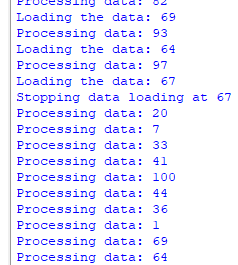
Gradient_thread_1 = ∇Loss(Data_subset_1, Model_parameters) Average_Gradient = (Gradient_thread_1 + Gradient_thread_2 + ... + Gradient_thread_n) / n Model_parameters = Model_parameters - Learning_rate * Average_Gradient It's important to note that implementing threading for machine learning tasks can be complex and may require careful synchronization to ensure correctness and avoid race conditions. Additionally, the effectiveness of threading depends on the hardware and software infrastructure being used. In practice, many machine learning frameworks and libraries, such as TensorFlow and PyTorch, provide tools and abstractions for easily incorporating threading or parallelism into your machine learning workflows without the need to write low-level threading code. These libraries can automatically manage the parallelization of computations for you. ============================================ Simulates a data processing pipeline where data is loaded into a queue, and a machine learning model consumes and processes the data: i) Create a FIFO queue data_queue with a maximum size of 10 to simulate a data processing pipeline. ii) The process_data function simulates a machine learning model processing data from the queue. It retrieves data from the queue, processes it (simulated by a sleep), and marks the task as done. iii) Create two threads, one for data loading and one for model processing The threads are started, and they run concurrently. iv) Data loading and model processing would continue indefinitely until the machine learning task is complete. Code: This program demonstrates how a queue can be used to manage the flow of data between different components of a machine learning system, ensuring that data is processed in a controlled and orderly manner. The script ends the loop of the load_data thread when it encounters the number 67. ============================================
|
||||||||
| ================================================================================= | ||||||||
|
|
||||||||