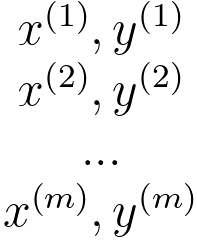=================================================================================
In machine learning, a learning algorithm is a fundamental component responsible for training a machine learning model. The learning algorithm is the mathematical or computational procedure that allows a model to learn from data, identify patterns, make predictions, or perform a specific task without being explicitly programmed for that task. The primary goal of a learning algorithm is to find the optimal set of model parameters or rules that can generalize from the training data to make accurate predictions or decisions on unseen or new data.
The terms "learning algorithm" and "estimator" are related but not exactly the same thing. They are often used interchangeably, but there is a subtle difference between the two.
-
Learning Algorithm:
- A learning algorithm refers to a specific mathematical or computational procedure used to train a machine learning model. It defines the steps that the model takes to learn from data and make predictions or decisions.
- Learning algorithms can encompass a wide range of techniques, such as linear regression, decision trees, support vector machines, neural networks, and more. Each of these algorithms has its own set of mathematical principles and optimization methods for learning from data.
- Learning algorithms are used to adjust the parameters of a model so that it can make accurate predictions based on the training data.
- Estimator:
- An estimator is a more general term that refers to a specific instance or implementation of a learning algorithm. In other words, an estimator is a concrete realization of a learning algorithm for a specific problem or dataset.
- Estimators are often associated with the scikit-learn library in Python, where they are used to fit models to data and make predictions. An estimator is an object with methods like fit() for training and predict() for making predictions.
- Scikit-learn's estimators follow a consistent API, making it easy to work with different types of models in a standardized way.
Therefore, while all estimators are based on learning algorithms, not all learning algorithms are necessarily associated with a specific estimator in the scikit-learn sense. Estimators are a practical implementation of learning algorithms that follow a common interface, making it easier to use and interchange different machine learning models in a consistent manner, especially in the context of the scikit-learn library.
Here are some key characteristics and steps involved in a typical machine learning learning algorithm:
-
Data Input: Learning algorithms require a dataset as input. This dataset consists of examples, where each example includes input features and their corresponding labels (for supervised learning) or just input features (for unsupervised learning).
-
Model Initialization: The learning algorithm initializes a model with some initial parameters or rules. The model represents the hypothesis or function that relates the input features to the output.
-
Training Phase: In supervised learning, the algorithm adjusts the model's parameters iteratively to minimize a predefined cost or loss function. The optimization process aims to make the model's predictions as close as possible to the true labels in the training data. This is typically done through techniques like gradient descent or more advanced optimization methods.
-
Generalization: The goal of the learning algorithm is not just to fit the training data well but to generalize to unseen data. Generalization ensures that the model can make accurate predictions on new, previously unseen examples.
-
Hyperparameter Tuning: Learning algorithms may involve tuning hyperparameters, which are settings or configurations that control the learning process but are not learned from the data. Examples include the learning rate in gradient descent or the depth of a decision tree.
-
Evaluation: After training, the model's performance is evaluated using a separate validation dataset or through cross-validation to assess how well it will perform on new, unseen data.
-
Deployment: Once a satisfactory model is obtained, it can be deployed in a real-world application to make predictions or decisions based on new input data.
There are various types of learning algorithms, each suited for different types of problems and data. These include supervised learning algorithms (e.g., regression and classification), unsupervised learning algorithms (e.g., clustering and dimensionality reduction), and reinforcement learning algorithms (used for sequential decision-making tasks). Additionally, there are semi-supervised and self-supervised learning methods that combine aspects of both supervised and unsupervised learning. The choice of the learning algorithm depends on the specific problem you are trying to solve and the nature of your data.
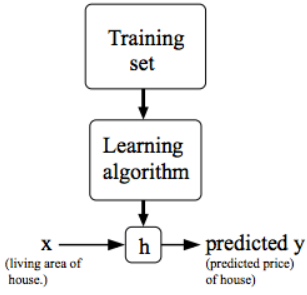
Figure 3908a shows how supervised learning works. To provide a precise characterization of the supervised learning problem, the objective is to acquire a function h: X → Y from a given training set. This function, denoted as h(x), should excel at predicting the associated value y. Traditionally, this function h is referred to as a "hypothesis" due to historical conventions.
Figure 3908a. (a) Workflow of supervised learning, and (b) Training data set. |
There are numerous algorithms used in machine learning, each designed for specific tasks and scenarios:
- Linear Regression
- Logistic Regression
- Decision Trees
- Random Forest
- Support Vector Machines (SVM)
- Naive Bayes
- k-Nearest Neighbors (k-NN)
- Neural Networks (Deep Learning)
- Gradient Boosting (e.g., XGBoost, LightGBM)
- Principal Component Analysis (PCA)
- K-Means Clustering
- Hierarchical Clustering
- Gaussian Mixture Models (GMM)
- Hidden Markov Models (HMM)
- Reinforcement Learning Algorithms (e.g., Q-Learning, DDPG)
Even though it can be a bit oversimplified, at some degree, we can still say that gradient descent and linear regression is one of hte most widely used learning algorithms in the world today:
-
Linear Regression: Linear regression is widely used, especially for solving regression problems, where the goal is to predict a continuous output. It's simple, interpretable, and serves as a fundamental building block for more complex models.
-
Gradient Descent: Gradient descent is not an algorithm for learning a specific model but rather an optimization technique used to train a wide range of machine learning models, including neural networks, support vector machines, and linear regression. It's essential for updating model parameters to minimize a loss function, making it a crucial component of many learning algorithms.
Whether the hypothesis obtained from a machine learning process is a random variable or not depends on various factors, and it's not only determined by whether the input data is a random variable. Table 3908 list the randomness of hypothesis depending on learning algorithms and input data in the learning process of "data > learning algorithm > hypothesis".
Table 3908. Randomness of hypothesis depending on learning algorithms and input data.
| Input data |
Learning algorithm |
Hypothesis |
| Random variable |
Deterministic Function |
Random variable |
| Random variable |
Linear Regression |
Not random variables |
| Random variable |
Logistic Regression |
Not typically random variables |
| Random variable |
Decision Trees |
Not random variables |
| Random variable |
Random Forest |
Not random variables |
| Random variable |
Naive Bayes |
Not random variables, but rather a probabilistic model that describes the relationships between the input random variables and the output classes. |
============================================
|