Learning Rate - Python for Integrated Circuits - - An Online Book - |
||||||||
| Python for Integrated Circuits http://www.globalsino.com/ICs/ | ||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||
================================================================================= Determining the learning rate in gradient descent is a critical hyperparameter tuning task, as it can significantly affect the convergence and performance of your machine learning model. There are several methods to determine an appropriate learning rate:
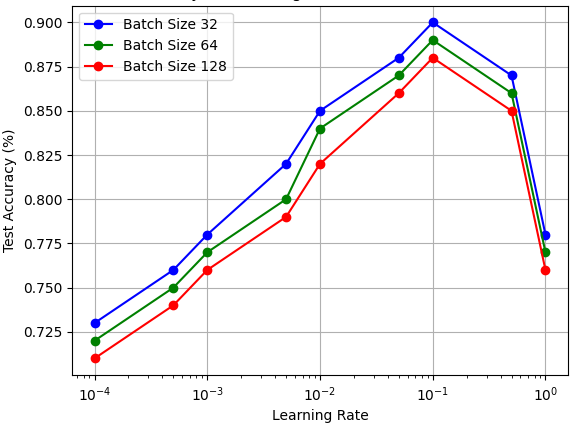
Note that the optimal learning rate can vary depending on the model architecture, dataset, and problem. Therefore, it's often necessary to experiment with different learning rates and validation strategies to find the best one for your specific task. Regularly monitoring your model's performance during training and adjusting the learning rate accordingly is a good practice for achieving fast and stable convergence. Choice of Learning Rate: 1. In the gradient-based optimization algorithms like gradient descent, the learning rate () is a hyperparameter that determines the step size at each iteration. It controls how quickly or slowly the algorithm converges to the optimal solution. 2. The learning rate is a hyperparameter that determines the size of the step that is taken during the optimization process in weight space. Weight space refers to the space of possible values for the parameters (weights) of a machine learning model. When training a machine learning model, the goal is often to minimize a certain objective function (e.g., a loss function) by adjusting the weights of the model. The learning rate plays a crucial role in this process. If the learning rate is too small, the model may take a long time to converge or may get stuck in a local minimum. On the other hand, if the learning rate is too large, the optimization process may oscillate or even diverge, making it difficult to find the optimal set of weights. 3. When performing linear regression, someone can choice η to be 1/n. Here, n is the size of the dataset. That is, the learning rate is inversely proportional to the dataset size. If represents the number of data points in your linear regression dataset, then the learning rate is set as times some constant. However, the practical η is usually larger than 1/n; otherwise, the process will be very slow. Therefore, the learning rate is a hyperparameter that controls how much to change the model in response to the estimated error each time the model weights are updated. Choosing the learning rate is challenging: 3.a. Training may take a long time if the value is too small. 3.b. A large learning rate value may result in the model learning a sub-optimal set of weights too fast or an unstable training process. 4. In general, the choice of the learning rate in gradient descent is typically a hyperparameter that needs to be tuned empirically. There is no one-size-fits-all learning rate, and it can vary depending on the specific problem and dataset. 5. The learning rate should be chosen based on experimentation and validation on your specific dataset and problem. Common values for learning rates often fall in the range of 0.1, 0.01, or 0.001, but these values are not fixed and may need adjustment. 6. The learning rate is a configurable hyperparameter used in the training of neural networks. In neural networks, the learning rate is typically set to a small positive value to ensure that the optimization process converges slowly and avoids overshooting the minimum of the loss function. The range between 0.0 and 1.0 is common, but learning rates can also be set outside this range based on the specific requirements of the task. 7. Smaller batch sizes require larger learning rates. Figure 3903 shows the test accuracy depending on learning rates. When the learning rate is too small, the model may take a long time to converge, i.e., to reach a minimum in the loss function. On the other hand, if the learning rate is too large, the model might overshoot the minimum and fail to converge:
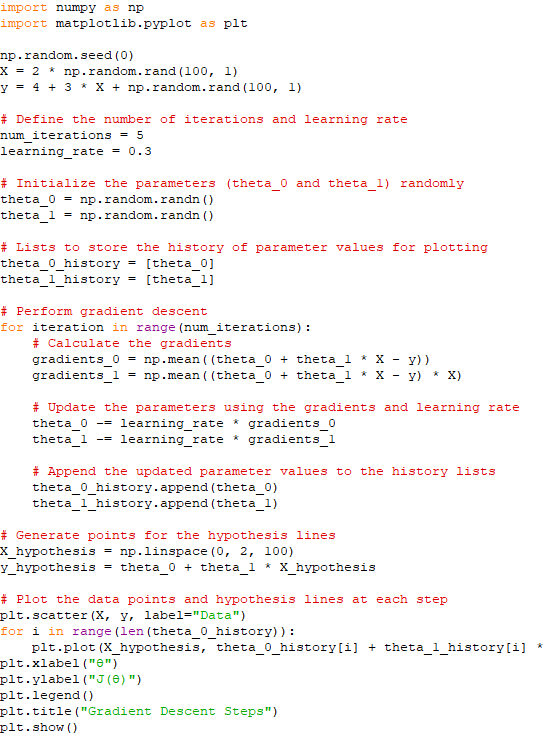
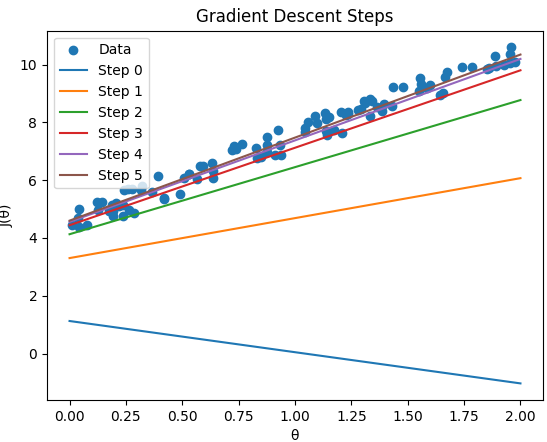
Figure 3903. Test accuracy depending on learning rates (Code). The dependence of loss on the initial learning rate, ls_init_learn_rate in logistic regression in BigQuery ML, has been discussed in page3535. ============================================ The script below shows the steps of example gradient descent and plots the hypothesis lines after each step with linear regression model, depending on learning rate. Code: This script shows how the gradient descent algorithm iteratively adjusts the parameters of a linear regression model to find the best-fitting line for the given data.
|
||||||||
| ================================================================================= | ||||||||
|
|
||||||||