=================================================================================
Table 3874. Logistic regression versus linear regression.
| |
Linear Regression |
Logistic regression |
| Equation |
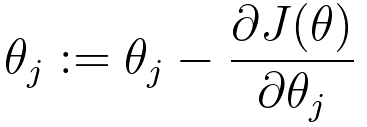 |
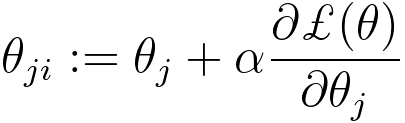 |
| Optimization |
Optimize squared cost function |
Optimize log likelihood |
| Method |
Minimize the error |
Maximize the log-likelihood |
Linear regression:
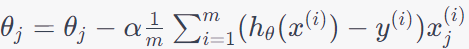 ----------------------------- [3874a] ----------------------------- [3874a]
Logistic regression:
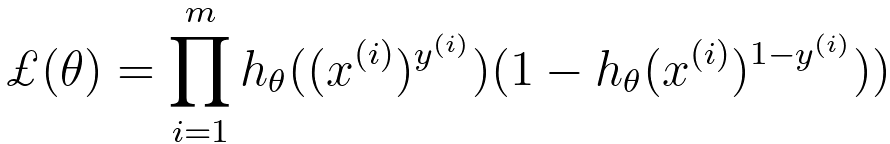 ---------------------- [3874b] ---------------------- [3874b]
While linear regression and logistic regression share some similarities in their underlying algorithms, they serve different purposes and are not interchangeable. Here's why linear regression is not suitable for logistic regression:
-
Different Output Types:
- Linear Regression: Linear regression is used for predicting continuous numerical values. It models the relationship between independent variables and a continuous dependent variable.
- Logistic Regression: Logistic regression is used for binary classification problems where the output is categorical (e.g., 0 or 1, True or False). It models the probability that a given input belongs to a particular class.
- h(θ) definitions are different:
- Linear Regression: h(θ) = θ₀ + θ₁x₁ + θ₂x₂ + ... + θnxn.
- Logistic Regression: h(θ) = 1/(1 + e^(-θ₀ - θ₁x₁ - θ₂x₂ - ... - θnxn)).
- Output Range:
- Linear Regression: The output of linear regression is a real number that can span a wide range of values, from negative infinity to positive infinity.
- Logistic Regression: The output of logistic regression is a probability value between 0 and 1, representing the likelihood of belonging to a particular class.
- Activation Function:
- Linear Regression: In linear regression, there is no activation function applied to the output. The model simply computes a weighted sum of the input features.
- Logistic Regression: Logistic regression uses the logistic (sigmoid) activation function to squash the output into the range [0, 1]. This transformation is crucial for modeling probabilities.
- Loss Function:
- Linear Regression: Linear regression typically uses the mean squared error (MSE) loss function, which measures the squared difference between predicted and actual values.
- Logistic Regression: Logistic regression uses the logistic loss function (also known as the cross-entropy or log loss) to measure the dissimilarity between predicted probabilities and true class labels.
- Interpretation:
- Linear Regression: The coefficients in linear regression represent the change in the dependent variable associated with a one-unit change in the independent variable.
- Logistic Regression: The coefficients in logistic regression represent the change in the log-odds of the probability of the positive class associated with a one-unit change in the independent variable.
The normal equations, which are used to find the optimal parameters (coefficients) in linear regression, do not have a direct equivalent in logistic regression. Logistic regression uses a different method for parameter estimation, typically involving iterative optimization algorithms.
In linear regression, you can find the optimal parameters analytically using the normal equations, which minimize the mean squared error (MSE). This analytical solution provides the coefficients that minimize the error directly.
In logistic regression, the objective is to maximize the likelihood function or minimize the logistic loss (also known as the cross-entropy loss) to estimate the parameters. This optimization problem does not have a closed-form solution like the normal equations. Instead, you typically use iterative optimization techniques such as gradient descent, Newton's method, or other optimization algorithms to find the optimal values of the parameters.
============================================
|