Table 3801. Frequentist approach versus Bayesian approach.
| |
Frequentist approach |
Bayesian approach |
| Equation |
P(s|θ) |
P(θ) |
| Probability Interpretation |
Probability represents the long-run frequency of events or outcomes.
Probabilities are associated with the frequency or long-run behavior of events. In particular, P(s|θ) represents the probability of observing data (s) given a fixed but unknown parameter (θ). |
Probability represents degrees of belief or uncertainty.
Probabilities represent degrees of belief or uncertainty, not just frequencies. P(θ) represents the probability distribution of a parameter (θ), which reflects our belief or uncertainty about the parameter before observing data. |
| Parameter Treatment |
Parameters are treated as fixed but unknown constants. They are not assigned probabilities, but data-related quantities are.
Frequentists view parameters (θ) as fixed, but unknown constants. They do not assign probabilities to parameters themselves, but rather to data and data-related quantities. |
Parameters are treated as random variables with probability distributions. Prior beliefs are expressed through a prior distribution, and the posterior distribution is updated based on data.
Bayesian statisticians assign prior probabilities to parameters based on their existing knowledge or beliefs. This is called the prior distribution. After observing data, they update these beliefs using Bayes' theorem to obtain the posterior distribution, P(θ|s), which represents the updated belief about the parameter after considering the data. |
| Prior Information |
Does not explicitly incorporate prior information or beliefs into the analysis. |
Incorporates prior beliefs or knowledge about parameters through the prior distribution. This allows for a systematic way to update beliefs. |
| Point Estimates vs. Probability Distributions |
Inference often involves point estimates, such as maximum likelihood estimates. Confidence intervals provide intervals for parameters. |
Inference results in probability distributions for parameters (posterior distribution), capturing the uncertainty about parameter values. |
| Hypothesis Testing |
Hypothesis testing is common, with tests like t-tests and chi-squared tests. It involves p-values to assess the evidence against null hypotheses. |
Hypothesis testing is performed through comparing posterior distributions, and the interpretation is based on the probability of a parameter falling within a certain range. |
| Data-Parameter Relationship |
Data is considered random, and parameters are fixed. Likelihood functions describe the relationship between data and parameters. |
Data is fixed, and parameters are treated as random. Posterior distribution combines prior information and likelihood to update beliefs about parameters. |
| Handling of Uncertainty |
Uncertainty is typically expressed through confidence intervals and hypothesis testing results. |
Uncertainty is explicitly represented as probability distributions, making it easier to communicate and reason about uncertainty. |
| Inference |
Inferences in frequentist statistics often involve point estimates, confidence intervals, and hypothesis tests. For example, they might estimate a parameter like the mean of a population based on a sample and construct confidence intervals to make statements about the likely range of the parameter. |
Bayesian inference results in probability distributions for parameters rather than point estimates. This means that, in Bayesian statistics, we express our uncertainty about parameters as probability distributions, not fixed values. |
| Computational Complexity |
Inference is often computationally straightforward, especially for common frequentist methods. |
Bayesian inference can be more computationally intensive, particularly when using complex models and sampling techniques like Markov Chain Monte Carlo (MCMC). |
| Subjectivity |
Often considered more objective since it does not rely on subjective prior distributions. |
Involves subjectivity in specifying the prior distribution, which can lead to different results based on different prior choices. |
| Regularization |
They provide different frameworks for handling and incorporating regularization techniques into models. |
| Frequentist approaches often use L1 (Lasso) and L2 (Ridge) regularization techniques to constrain the magnitude of model parameters. In a frequentist, regularization is often applied by adding penalty terms to the loss function during model training. These penalty terms help prevent overfitting and encourage simpler models. |
Bayesian methods allow for regularization through the specification of prior distributions on model parameters. By assigning suitable prior distributions, you can encode prior beliefs about the values of the parameters and control their uncertainty. This acts as a form of regularization, guiding the model to favor certain parameter values. |
| Frequentist techniques, like cross-validation, can be used to tune the regularization hyperparameters (e.g., λ in Ridge and Lasso regression) by systematically evaluating model performance on different subsets of the data. |
Bayesian neural networks (BNNs) are a type of neural network that incorporates Bayesian principles. BNNs naturally handle model uncertainty by treating neural network weights as random variables with prior distributions. This naturally provides regularization, as the posterior distribution over weights is updated based on the data. |
| Early stopping, which is a form of regularization, is commonly employed in frequentist methods like neural networks to prevent the model from overfitting. It involves monitoring the model's performance on a validation set during training and stopping the training process when performance starts to degrade. |
In Bayesian frameworks, variational inference can be used to approximate complex posterior distributions over model parameters. Variational methods can be used to encourage simpler posterior distributions, which can act as regularization. |
| Applications |
Maximum Likelihood Estimation (MLE)
Hypothesis Testing
Bootstrap Resampling
Cross-Validation
Frequentist Neural Networks |
Bayesian Inference
Bayesian Networks
Bayesian Optimization
Bayesian Deep Learning
Bayesian Regularization
Variational Inference
Probabilistic Graphical Models |
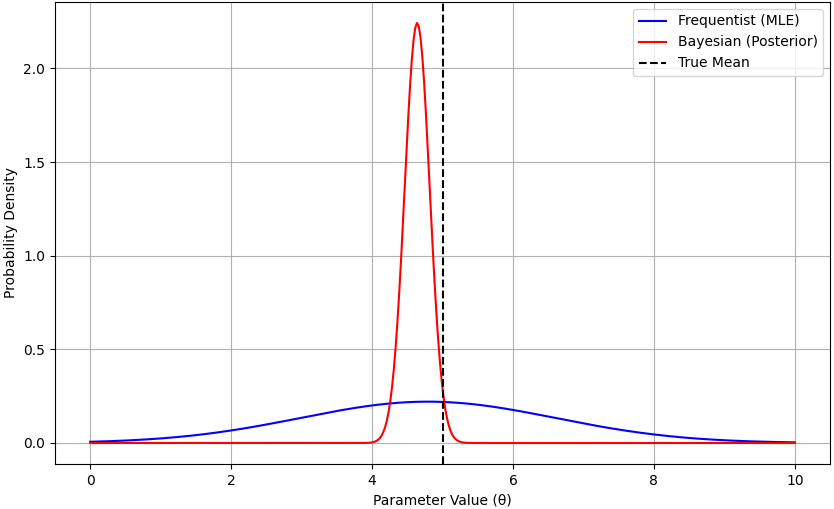
Figure 3801 shows the comparison between frequentist approach versus Bayesian approach.