=================================================================================
K-Fold Cross-Validation is a technique used in machine learning and statistics to assess the performance of a predictive model. It helps in estimating how well a model will generalize to new, unseen data. In fact, it's often recommended for small datasets to maximize the use of available data and obtain a more reliable estimate of your model's performance. The main idea behind K-Fold Cross-Validation is to split the available dataset into K equally sized "folds" or subsets, where K is typically a positive integer, often chosen as 5 or 10. The process can be summarized as follows by assuming you have a dataset with 100 samples, you can perform 5-Fold Cross-Validation:
-
Data Splitting: The dataset is randomly partitioned into K subsets of approximately equal size. In the mentioned example, these subsets are referred to as "folds." Divide your dataset into 5 roughly equal-sized folds. Each fold will contain 20 samples (100 samples / 5 folds).
-
Training and Testing: The model is trained and evaluated K times. In each iteration, one of the K folds is used as the test set, and the remaining K-1 folds are used for training the model. This process ensures that each fold is used as a test set exactly once, and the remaining data is used for training.
In the mentioned example above, you will train and evaluate your model 5 times, each time using a different fold as the test set and the remaining 4 folds as the training set. Here's how it works:
- Iteration 1: Fold 1 as the test set, Folds 2, 3, 4, and 5 as the training set.
- Iteration 2: Fold 2 as the test set, Folds 1, 3, 4, and 5 as the training set.
- Iteration 3: Fold 3 as the test set, Folds 1, 2, 4, and 5 as the training set.
- Iteration 4: Fold 4 as the test set, Folds 1, 2, 3, and 5 as the training set.
- Iteration 5: Fold 5 as the test set, Folds 1, 2, 3, and 4 as the training set.
- Performance Evaluation: For each iteration, the model's performance is assessed on the test fold using a chosen evaluation metric (e.g., accuracy, mean squared error, etc.). The results from all K iterations are then typically averaged to obtain a more robust estimate of the model's performance.
In the mentioned example above, for each iteration, you train your model on the training set and evaluate its performance on the corresponding test set. You record the performance metric (e.g., accuracy, mean squared error) for each fold.
-
Final Model Selection: After performing K-Fold Cross-Validation, you can use the average performance metric to choose the best model or make necessary adjustments to your model to improve its performance.
In the mentioned example above, after completing all 5 iterations, you will have 5 performance metrics, one for each fold. You can calculate the average (mean) and standard deviation of these metrics to assess the model's overall performance.
- Final Step: The final step in K-Fold Cross-Validation typically involves refitting the model on the entire dataset, which means using 100% of the available data to train the final model. This is a common practice in cross-validation workflows. That is, once we have determined the best model or configuration, you typically retrain the model using all available data (100%) to create a final model. The final model is the one we intend to deploy or use for making predictions on new, unseen data. It benefits from having been trained on the entire dataset, which often leads to better overall performance compared to models trained on a subset of the data in each fold.
K-Fold Cross-Validation has several advantages, including a more reliable estimate of a model's performance compared to a single train-test split, as it uses multiple subsets of the data. It also helps detect overfitting because the model is evaluated on multiple test sets. Additionally, it allows you to make the most of your available data for both training and testing, which is particularly valuable when the dataset is limited.
In the mentioned example above, by applying 5-Fold Cross-Validation in this manner, you effectively use all of your 100 samples for both training and testing, and you obtain a more reliable estimate of your model's performance. It helps you assess how well your model generalizes to different subsets of your data and can be used for model selection, hyperparameter tuning, and understanding the model's behavior on your specific dataset, even with limited data.
Common variants of K-Fold Cross-Validation include stratified K-Fold, where the class distribution in each fold is approximately the same as in the whole dataset (useful for imbalanced datasets), and nested K-Fold, which is used for hyperparameter tuning.
As an example, Figure 3791a shows 4-fold cross-validation with 40 samples in total. In a 4-Fold Cross-Validation, you train and evaluate your model four times, once for each of the four folds. Each of these iterations is like a separate training and testing process.
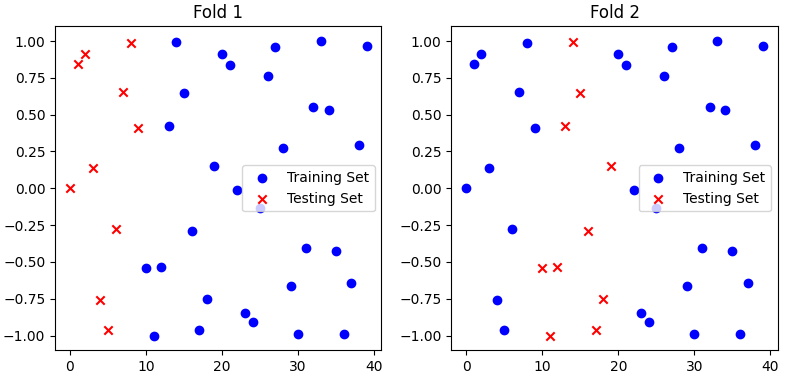
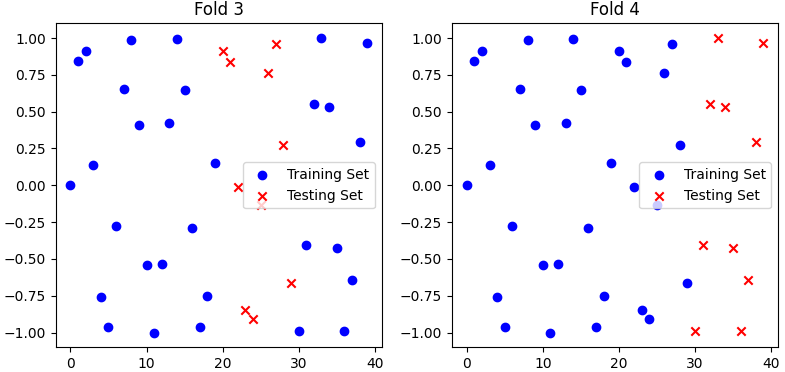
Figure 3791a. 4-fold cross-validation with 40 samples in total. (code)
Figure 3791b shows the errors after each iteration in K-Fold Cross-Validation. The final error of the K-Fold Cross-Validation is the average of the errors in all iterations, which is 0.4793.
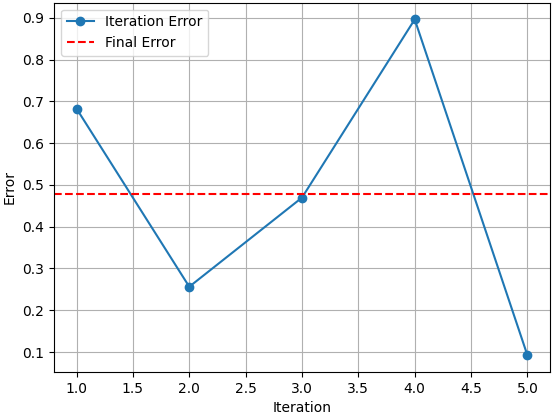
Figure 3791b. Errors after each iteration in K-Fold Cross-Validation. (code)
Random shuffling is a common and generally accepted practice when it comes to K-Fold Cross-Validation. Shuffling the data helps ensure that the data samples are distributed randomly across the folds, reducing the risk of bias or patterns in the data affecting the performance evaluation of the model:
-
Reduces Bias: Without shuffling, if the data has some inherent order or structure, such as being sorted by class labels, time, or some other factor, not shuffling could result in certain folds being dominated by one class or certain patterns, which could lead to biased model evaluation.
-
Generalization: Shuffling helps ensure that the model is exposed to a representative mix of data in each fold. This is crucial for evaluating how well the model generalizes to unseen data, which is the primary goal of cross-validation.
-
Robustness: Shuffling makes the K-Fold Cross-Validation process more robust. It helps prevent the performance estimates from being overly sensitive to the initial order of the data.
-
Randomness: In many real-world scenarios, data can be randomly ordered or collected. Shuffling the data makes the cross-validation procedure more representative of these real-world scenarios.
However, there might be some cases where you wouldn't want to shuffle your data, such as when working with time-series data or specific structured datasets where the order is significant, and you want to maintain temporal or structural integrity. In these cases, you may choose not to shuffle the data and consider using techniques like time series cross-validation or grouped cross-validation, which take the temporal or structural dependencies into account.
The advantages of K-Fold Cross-Validation are:
-
Robust Performance Estimate: K-Fold Cross-Validation provides a more robust estimate of a model's performance compared to a single train-test split. It reduces the risk of obtaining performance metrics that are overly optimistic or pessimistic due to the specific split of data.
-
Effective Use of Data: It allows you to make the most efficient use of your available data. By repeatedly splitting the dataset into training and test sets, K-Fold Cross-Validation ensures that every data point is used for both training and testing at least once.
-
Detection of Overfitting: By evaluating the model on multiple test sets, K-Fold Cross-Validation helps in identifying whether the model is overfitting the training data. If the model's performance varies significantly across different folds, it may be a sign of overfitting.
-
Model Comparison: It facilitates the comparison of different models or different hyperparameter settings, as each model can be evaluated in the same way, using the same data splits.
-
Useful for Small Datasets: K-Fold Cross-Validation is particularly valuable when working with small datasets, where the limited amount of data makes it essential to squeeze as much information as possible from each data point. It helps in obtaining a more robust estimate of the model's performance since small datasets are more susceptible to random variations.
The disadvantages of K-Fold Cross-Validation are:
-
Computational Cost: Performing K-Fold Cross-Validation requires training and evaluating the model K times, which can be computationally expensive, especially when dealing with large datasets or complex models.
-
Data Leakage in Feature Selection: When using feature selection or feature engineering techniques within each fold, there's a risk of data leakage, as the model may indirectly learn information from the test data during feature selection. To mitigate this, feature selection should be done outside the cross-validation loop.
-
Variability in Results: The results of K-Fold Cross-Validation can be sensitive to the choice of K. Smaller values of K may lead to more variability in performance estimates, while larger K values can be more stable but require more computational resources.
-
May Not Reflect Real-world Deployment: While K-Fold Cross-Validation provides a good estimate of model performance on the available dataset, it may not fully represent the model's performance in a real-world deployment, where data distribution can change over time or across different scenarios.
-
Stratification Challenges: In some cases, it may be challenging to create meaningful stratified splits, especially for imbalanced datasets or when certain groups are underrepresented in the data.
- Small Datasets: K-Fold Cross-Validation can be computationally expensive, especially for small datasets, as it requires training and evaluating the model K times. In such cases, simpler validation techniques like hold-out validation or leave-one-out cross-validation may be more practical.
- Large Datasets: The computational cost of K-Fold Cross-Validation becomes more manageable with larger datasets, but it may still be a consideration for very large datasets or when training complex models.
- Rarely used in deep learning: Deep learning models often require a large amount of data to train effectively. In most cases, the available dataset may be so large that splitting it into K-Folds for cross-validation becomes computationally expensive and time-consuming. In such cases, researchers might opt for other techniques like hold-out validation or stratified sampling.
============================================
|