=================================================================================
Forward search is a feature selection method in machine learning that starts with an empty set of features and incrementally adds one feature at a time to build a subset of features. The goal is to select the most relevant and informative features for a given machine learning task. Forward search is a greedy search algorithm and is commonly used for feature selection in the context of classification, regression, or other predictive modeling tasks.
The general process of forward search in feature selection typically involves the following steps:
-
Initialization: Start with an empty set of features, often denoted as f or φ, namely, feature set f = φ. This empty set represents no features selected initially.
At this stage, h(x) = θ0.
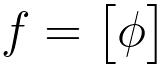 --------------------------------- [3890a] --------------------------------- [3890a]
-
Feature Evaluation: Evaluate each feature independently to determine its relevance to the learning task. This evaluation is often done using a specific criterion or metric, such as a scoring function or performance measure (e.g., accuracy, F1-score, or mutual information). You can use techniques like correlation, mutual information, or statistical tests to assess feature relevance.
-
Feature Selection: Select the feature that has the highest evaluation score and add it to the feature set. This feature becomes the first feature in the selected subset.
-
Iteration: For each iteration, evaluate the remaining unused features, select the one with the highest score, and add it to the selected feature set. For each feature i not already in the set f, evaluate the impact of adding feature i to the feature set f. This evaluation is done based on a specific criterion, which can vary. Typically, the criterion is based on the performance of a machine learning model using the selected features on a development (dev) set or through some statistical measure.
At each iteration, h(x) = θ0θ1...θixn. Here, there is n features in total.
-
Select the best feature: Choose the feature i that, when added to the current feature set f, results in the most significant improvement in the model's performance on the dev set, as determined by the chosen criterion. This feature is selected for inclusion in the feature set.
-
Update the feature set: Add the selected feature i to the feature set f.
For instance, if the feature 3 is the most pronounced, then we set the feature g = {x3}:
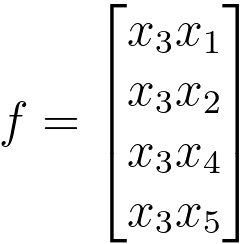 --------------------------------- [3890b] --------------------------------- [3890b]
-
Repeat: Repeat the process iteratively. Continue this process iteratively until a predefined stopping criterion is met. The stopping criterion could be a set number of features to select, a certain level of performance improvement, or other factors specific to the problem at hand.
Use Equation 3890b to find which feature in the rest features is the second most pronounced for helping the algorithm. Assuming it is feature x4, then we connect x4 by g = {x3x4} and repeat step 2 above.
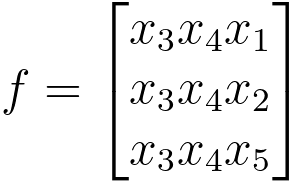 --------------------------------- [3890c] --------------------------------- [3890c]
Keep adding features until the addtional feature hurts the performance, then you get the best choice of feature subset which allows you to have the best possible performance of dev set. That is, continue this process until a predetermined stopping criterion is met (e.g., a fixed number of features is reached or performance on a validation set starts to degrade).
- Model Training and Evaluation: After selecting a subset of features, train a machine learning model (e.g., a classifier or regressor) using the chosen features and assess its performance using a validation or test dataset.
- Validation and Refinement: Depending on the model's performance, you may further refine the selected feature set by adding or removing features and re-evaluating the model's performance.
- Stopping Criteria: The forward search process can be stopped based on various criteria, such as a maximum number of features to select, a predefined performance threshold, or a specific time limit.
Forward search, as a feature selection method, has its advantages and disadvantages:
Advantages of Forward Search:
-
Simple and Intuitive: Forward search is easy to understand and implement. It follows a straightforward and intuitive process, making it accessible to practitioners without extensive expertise in feature selection.
-
Efficient for Small Feature Spaces: When dealing with relatively small feature spaces, forward search can be an effective method for identifying relevant features without a substantial computational burden.
-
Incremental Feature Selection: It incrementally adds features to the selected subset, allowing you to explore the importance of individual features and their impact on the model's performance.
-
Potential for Good Results: In some cases, forward search can lead to a good feature subset that improves the model's predictive performance, especially if there are strong, clear-cut features that are highly relevant to the problem.
Disadvantages of Forward Search:
-
Combinatorial Complexity: Forward search explores all possible feature combinations, which can become computationally expensive as the number of features increases. This limits its practicality for datasets with a large number of features.
-
No Consideration of Feature Interactions: Forward search evaluates features independently and doesn't consider interactions between features. It may miss important feature interactions that can be crucial for accurate modeling.
-
Risk of Overfitting: The incremental addition of features may lead to overfitting if the model starts to perform well on the training data but generalizes poorly to unseen data. Proper validation and stopping criteria are essential to mitigate this risk.
-
Lack of Backtracking: Once a feature is added, forward search doesn't revisit feature subsets, meaning that if a suboptimal feature is added early in the process, it cannot be removed in later iterations.
-
High-Dimensional Data Challenges: In high-dimensional datasets, forward search can be impractical due to the large number of potential feature combinations. The search space becomes prohibitively large, and it may not be feasible to explore all combinations.
-
Not Suitable for All Problems: Forward search may not be the best choice for problems where the relationships between features are complex or not well understood. Other feature selection methods, such as wrapper methods or embedded methods, may be more appropriate in such cases.
============================================
|