Table 3726. Batch Gradient Descent (BGD), Stochastic Gradient Descent (SGD), Mini-Batch Gradient Descent, Batch Stochastic Gradient Descent, Momentum, (Adagrad, Adadelta, RMSprop), and Adam (Adaptive Moment Estimation).
| |
Batch Gradient Descent (BGD) |
Stochastic Gradient Descent (SGD) |
Mini-Batch Gradient Descent |
Batch Stochastic Gradient Descent |
Momentum |
Adagrad, Adadelta, RMSprop |
Adam (Adaptive Moment Estimation) |
| Definition |
This is the traditional form of gradient descent, where the entire training dataset is used to compute the gradient of the cost function with respect to the model parameters. The model parameters are then updated once per epoch (one pass through the entire dataset). BGD can be computationally expensive, especially for large datasets, as it requires storing and processing the entire dataset at once. |
In this variant, only one randomly chosen training sample is used to compute the gradient and update the parameters in each iteration. SGD can be more computationally efficient than BGD, especially for large datasets, but the updates can be noisy and may exhibit more variance. |
Mini-Batch Gradient Descent strikes a balance between BGD and SGD by using a mini-batch of n training samples to compute the gradient and update the parameters. The mini-batch size is a hyperparameter that can be adjusted. Mini-Batch Gradient Descent combines some advantages of both BGD and SGD, providing a compromise between computational efficiency and reduced variance in parameter updates. |
This is a hybrid approach that combines the ideas of batch and stochastic gradient descent. It involves dividing the training dataset into batches and updating the parameters after each batch. |
Momentum is a technique that helps accelerate SGD in the relevant direction and dampens oscillations. It introduces a moving average of the gradient to update the parameters. |
These are adaptive learning rate methods that adjust the learning rate during training based on the historical gradient information. They aim to converge faster and perform well on non-convex optimization problems. |
It is a popular optimization algorithm that combines ideas from both momentum and RMSprop. It maintains moving averages of both the gradients and the second moments of the gradients. |
| Key idea |
Update the model parameters based on the average gradient of the entire training dataset. |
|
|
|
|
|
|
| Advantages |
Its compatibility with vectorized operations. Vectorization allows you to perform operations on entire batches of data at once, leveraging the parallel processing capabilities of modern hardware, such as GPUs. This can significantly speed up the computation compared to processing individual data points sequentially. Implementing vectorized operations often involves using optimized linear algebra libraries (e.g., NumPy) that are highly efficient and take advantage of low-level optimizations. |
Its quick updates to the model parameters. |
|
|
|
|
|
| Convergence Speed |
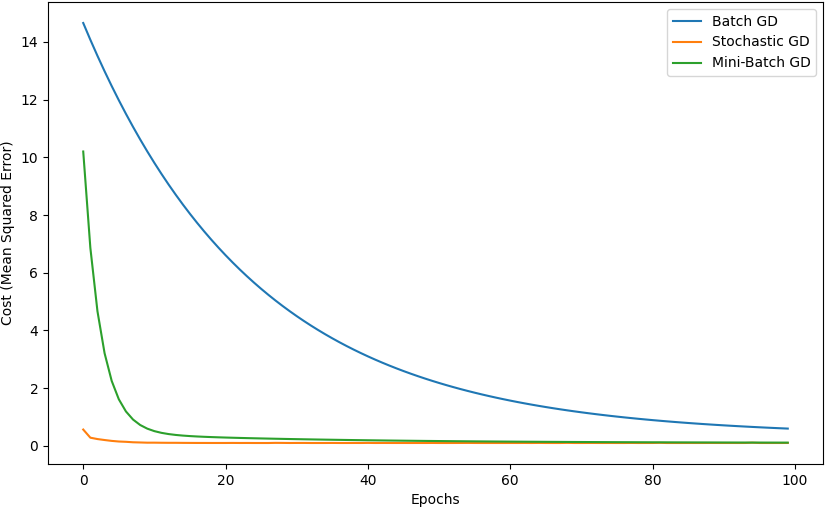
BGD updates the model parameters using the average gradient over the entire training dataset in each epoch. It usually converges smoothly, and you'll see a gradual decrease in the cost over epochs. |
SGD updates the model parameters for each training example. It may show more erratic behavior, with frequent fluctuations in the cost. It's faster per iteration but might have more variance. |
MBGD strikes a balance by updating the model parameters using a small batch of training examples. It often combines the advantages of both BGD and SGD, showing a smoother convergence compared to SGD. |
|
|
|
|
| Stability |
BGD provides a stable and smooth convergence since it considers the entire dataset in each iteration. |
SGD can be less stable due to its sensitivity to individual training examples, leading to more fluctuation in the cost. |
MBGD typically offers a balance between stability and speed, as it uses a mini-batch of data for updates. |
|
|
|
|
| Trade-offs |
BGD usually converges to the global minimum (assuming the cost function is convex), but it can be computationally expensive for large datasets. |
SGD and MBGD offer faster updates but might get stuck in local minima due to the stochastic nature of the updates. |
|
|
|
|
| Parameters |
θ or w: Model parameters/weights. |
θ or w: Model parameters/weights. |
θ or w: Model parameters/weights. |
|
|
|
|
| Dataset |
(X, y): Training data and labels. |
(xi, yi): Individual training data point and its label. |
(Xbatch, ybatch): Mini-batch of training data and labels. |
|
|
|
|
| Hyperparameters |
α (learning rate): Step size for parameter updates. |
α (learning rate): Step size for parameter updates. |
α (learning rate): Step size for parameter updates. |
|
|
|
|
| Update Rule |
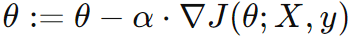 , ∇J(θ; X, y) is the gradient of the cost function with respect to the parameters. , ∇J(θ; X, y) is the gradient of the cost function with respect to the parameters. |
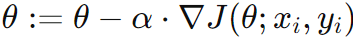 , where ∇J(θ; xi, yi) is the gradient of the cost function with respect to the parameters for a single data point. , where ∇J(θ; xi, yi) is the gradient of the cost function with respect to the parameters for a single data point. |
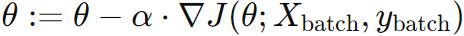 , where ∇J(θ; Xbatch, ybatch) is the gradient of the cost function with respect to the parameters for the mini-batch. , where ∇J(θ; Xbatch, ybatch) is the gradient of the cost function with respect to the parameters for the mini-batch. |
|
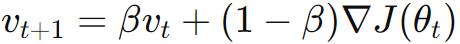
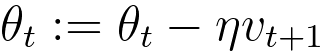
Momentum looks at the past update, but "normal" gradient decent does not look at the past updates in order to look for the right place to go. |
|
|
| Data Usage |
Uses the entire training dataset to compute the gradient of the cost function. |
Uses only one randomly chosen training sample to compute the gradient in each iteration. |
Uses a mini-batch of a specified size (between 1 and the total dataset size) to compute the gradient. |
|
|
|
|
| Convergence |
Tends to converge slowly, especially for large datasets, as it processes the entire dataset in each iteration. |
Can converge faster due to more frequent updates, but the updates are noisy and may exhibit more variance. |
Strikes a balance between BGD and SGD, offering a compromise between convergence speed and noise in updates. |
|
|
|
|
| Computational Efficiency |
Can be computationally expensive, especially for large datasets, as it requires processing the entire dataset in each iteration. |
Generally more computationally efficient since it processes only one data point at a time. |
Provides a middle ground in terms of computational efficiency, as it processes a small batch of data in each iteration. |
|
|
|
|
| Noise in Updates |
Updates are less noisy as they are based on the average gradient computed over the entire dataset. |
Updates are more noisy due to the use of only one data point at a time. That is, the direction of the gradient is quite noisy:
The gradient is computed based on a single randomly chosen data point in each iteration. Because of this randomness, the computed gradient at each iteration can be highly variable, leading to noisy updates. The noise arises from the fact that a single data point may not be representative of the overall dataset, and the gradient computed based on that single point may not accurately reflect the true direction of the steepest increase in the cost function. |
Offers a balance between noise levels, with updates based on a mini-batch.
The smaller the batch is, the more noise it has. |
|
|
|
|
| Convergence Path |
Produces a smoother convergence path due to the use of the entire dataset in each iteration. |
Can have a more erratic convergence path due to the randomness introduced by using only one data point. |
Offers a compromise, with a relatively smoother convergence path compared to SGD. |
|
|
|
|
| Learning Rate Adjustment |
Learning rate can be adjusted based on the entire dataset. |
Learning rate needs to be carefully tuned and may require adaptive techniques due to the noisy updates. |
Learning rate adjustment can be based on the mini-batch, providing some adaptability. |
|
|
|
|
| Memory Usage |
Requires enough memory to store the entire dataset. |
Requires less memory as it processes one data point at a time. |
Requires moderate memory, depending on the chosen mini-batch size. |
|
|
|
|
| Graph |
|
|
|
|
|