|
||||||||
Grid World Navigation - Python Automation and Machine Learning for ICs - - An Online Book - |
||||||||
| Python Automation and Machine Learning for ICs http://www.globalsino.com/ICs/ | ||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||
================================================================================= The Grid World Navigation problem is a classic reinforcement learning task commonly used to study and test algorithms in the field of machine learning. The task involves an agent navigating through a grid-like environment to reach a goal while avoiding obstacles. The key components of the problem are:
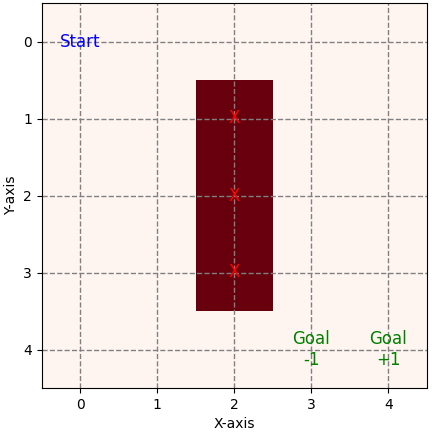
5.a. In Value Iteration, the agent learns a policy, a mapping from state to action, guiding its decisions at each state. However, our approach diverges by initially utilizing Value Iteration to learn a mapping of state to value, estimating rewards. Subsequently, the agent selects actions at each state based on these reward estimates, aiming to maximize cumulative rewards by choosing the actions associated with the highest estimated rewards. Researchers and practitioners use the Grid World Navigation problem as a simplified testbed to develop and evaluate reinforcement learning algorithms before applying them to more complex real-world tasks. It serves as a foundation for understanding concepts such as state, action, reward, and the exploration-exploitation trade-off in reinforcement learning. As an example, the guideline of the navigation is straightforward: Your agent or robot commences its journey from the top-left corner (indicated as the 'start' position) and concludes at either Goal +1 or Goal -1, as shown in Figure 3683a, representing the corresponding reward. At each step, the agent has four feasible actions, namely up, down, left, and right. The red blocks signify impenetrable walls, barring the agent from passing through them. Initially, our implementation assumes determinism in actions—each action leads the agent precisely to its intended destination. For instance, if the agent opts for the "up" action at coordinates (2, 0), it will unfailingly land at (1, 0) rather than at (2, 1) or any other location. However, in the event of encountering a wall, the agent remains stationary at its current position.
Figure 3683a. Grid world navigation (code). Initially, the agent initializes the estimated values of all states ) to zero, The agent explores the environment by randomly moving within the grid. Initially, with no knowledge, the agent endures failures, but it learns from each iteration. An update rule commonly, which is associated with the update step for the value of a state , used in reinforcement learning and temporal difference learning is, where,
The corresponding steps and their corresponding parameter updates are: S0 a0 S1, ~ P(S0, a0) R(S0) + ϒR(S1) a1 S2, ~ P(S1, a1) ... R(S0) + ϒR(S1) + ϒ2R(S2) + ... The update rule signifies that the current estimate is adjusted by a fraction of the temporal difference [. This adjustment helps the agent update its value estimates based on the new information obtained from experiencing the transition from state to St+1. The learning rate influences the weight given to the new information in the update. In the navigation completion, The game resets when the agent reaches the end with a reward of +1 or -1, and rewards propagate backward, updating the estimated values of states encountered during the navigation. The agent evolves from an initial state of no knowledge, exploring and learning from failures. The update formula reflects how the estimated value of a state is adjusted based on the new information acquired during each iteration of game playing, influenced by the learning rate (). For example, if the agent moves from state to with a reward of 1, the new estimate of is calculated as . We can use a stochastic version to incorporate probabilities into the reinforcement learning update rule. In a simple case where the agent can take one of four actions (up, down, left, right) with equal probability. The update rule in this stochastic case would be, where:
Assuming the agent chooses each action with equal probability. In a stochastic environment, the probability of transitioning from state to state with action can be denoted as . If each action is equally likely, the probabilities can be set as follows, Then, the update rule becomes, This formula considers the equal probability of taking each action. In a more complex scenario, where action probabilities are different, these probabilities would be incorporated accordingly. If the agent has a 20% chance of moving in a different direction when heading north (or any other direction), we then need to introduce this stochasticity into the update equation. We can modify the equation to account for the probabilities associated with each action. Assuming the agent has an 80% chance of moving in the intended direction and a 20% chance of moving in a different direction, the update equation becomes more complex. Let's denote the intended action (e.g., moving north) as and the alternative actions (e.g., moving in other directions) as a'. The update equation with the stochasticity will be changed to, where:
This modification assumes an equal probability distribution among the alternative actions when the agent deviates from the intended direction. The probabilities and the update equation need to be adjusted accordingly if the actual probabilities are different. Based on reinforcement learning, if we consider the possibility of unintended movements due to uncertainties or stochasticity in the environment, we can introduce probabilities for each possible action. Let's assume that there's a 20% chance of going in the intended direction (down) and a 20% chance of going in each of the other three directions (up, left, right). In this case, the equations would involve calculating the expected value for each possible outcome. The equations for moving down, up, left, and right from position (3, 2) are as follows:
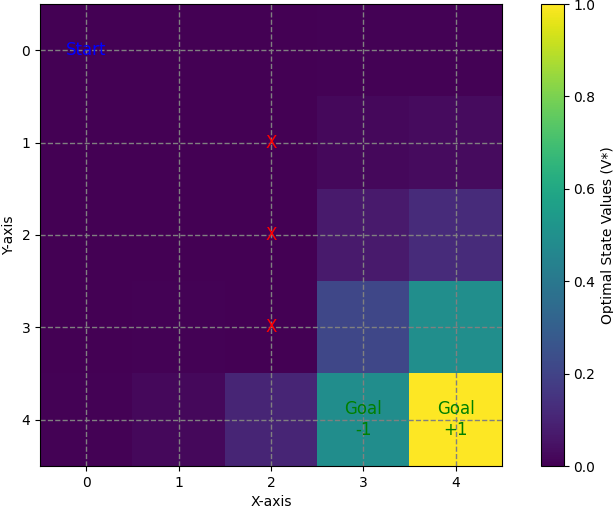
To combine the equations for the different directions (down, up, left, right) and represent the update for the state value , we can use a weighted sum of the expected values for each direction. Assuming a 20% probability for each direction, the update can be expressed as follows: where, Expected Valuestayrepresents the case where the agent stays in the current position. The probabilities (0.2 for each direction) indicate the likelihood of each action occurring. Figure 3683b shows the optimal value at each state.
Figure 3683b. Optimal value at each state (code). Insert the values in Figure 3683b into Equation 3683g, then we have, V(3,2) = 0.2*0.6 + 0.2*0.01 + 0.2*0.01 + 0.2*0.4 + 0.2*0.25 = 0.29 ----------------- [3683h] ============================================
|
||||||||
| ================================================================================= | ||||||||
|
|
||||||||