=================================================================================
Failure analysis processes in semiconductor labs indicate [1]:
-
Failure Analysis (FA) in semiconductor devices involves various methods to identify and localize failures. -
In FA, task times and workflows are highly variable, affected by factors like sample conditions and resource availability. The dynamic nature of the lab environment is shaped by stochastic events and non-deterministic decisions based on findings and device states.
-
The performance of an FA lab is typically measured by throughput or total analysis time. On the other hand, detection and localization of semiconductor failures is a knowledge-intensive and tedious task. Therefore, FA engineers and managers lack the capacity to oversee crucial lab processes, hindering efficient resource utilization.
-
Optimizing Key Performance Indicators (KPIs) can be challenging due to long and complex method sequences. KPIs are measurable values that demonstrate how effectively a company, organization, or individual is achieving key business objectives. The KPIs are used to evaluate the success or performance of activities and processes in relation to strategic goals. They provide a quantifiable way to assess progress over time and make informed decisions. In FA, the KPIs include metrics such as throughput (the rate at which tasks are completed or products are produced) and total analysis time (the time required to complete a particular analysis). These KPIs are used to measure the efficiency and effectiveness of the FA lab's operations.
-
Ad hoc processes may lead to blocked queues for specific tools and overload specialists, decreasing lab performance. "Ad hoc processes" refers to procedures or methods that are improvised or created on-the-fly to address a specific situation or need, rather than following a predetermined or standardized approach. Certain tasks or processes within the FA lab might be carried out in an unplanned or impromptu manner, without a structured or optimized workflow. These ad hoc processes can lead to inefficiencies, such as blocked queues for specific tools and overloading specialists, ultimately resulting in a decrease in the lab's overall performance.
-
Machine learning and statistical methods are used to estimate the workflow and duration of operations in IPI (Internal Physical Inspection) jobs. IPI refers to the process of examining the internal structure and components of a semiconductor device to identify defects, faults, or anomalies. This inspection is typically conducted using specialized equipment and techniques to analyze the physical properties and integrity of the semiconductor materials. As described below, algorithms of decision tree and random forest can be used in this application.
-
The resulting tool enables lab management to analyze and optimize the execution of IPI jobs. -
Information from the tool can be used in automated scheduling methods to improve resource utilization.
In the models of decision tree for optimizing the failure analysis processes, “if-then” rules are applied and evaluated, while traversing the decision tree from the root down to a leaf node, with consideration of the tree depth, representing the number of levels of tree. These models can be affected by the risk of overfitting and a high variance error. However, random Forest, shown in Figure 3475a, comes to mitigate these problems since a collection of trees is put together, whose results are aggregated at the end and results in an overall smaller variance error.
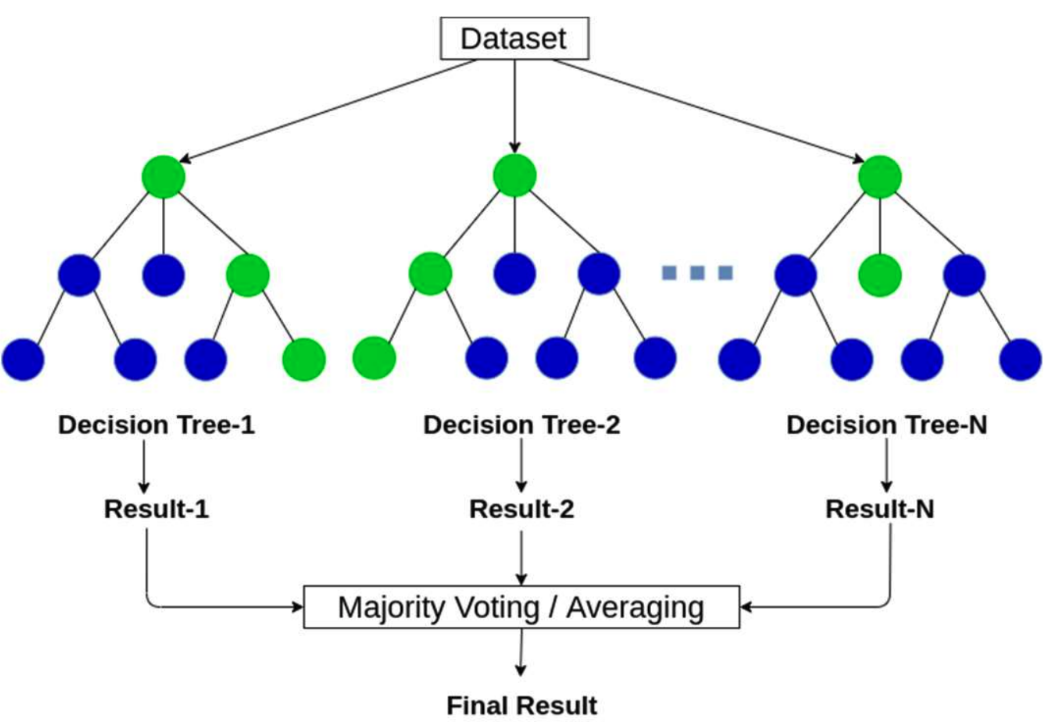
| Figure 3475a. Visual representation of random forest algorithm. [2] |
On the other hand, XGBoost is not suggested for such goal since the training of a single tree directly depends on the evaluation results of previous ones. [1]
============================================
[1] Domenico Pagliaro, Martin Pleschberger, Olivia Pfeiler, Thomas Freislich, and Konstantin Schekotihin, Working Time Prediction and Workflow Mining at Failure Analysis, ISTFA 2023: Proceedings of the 49th International Symposium for Testing and Failure Analysis Conference November 12—16, 2023, Phoenix, Arizona, USA https://doi.org/10.31339/asm.cp.istfa2023p0121.
[2] A. Sharma, "Random Forest vs Decision Tree | Which Is
Right for You?," 26 April 2023. [Online]. Available: https://www.analyticsvidhya.com/blog/2020/05/decision-tree-vs-random-forest-algorithm/.
|
