=================================================================================
Figure 3403 shows the big data lifecycle.
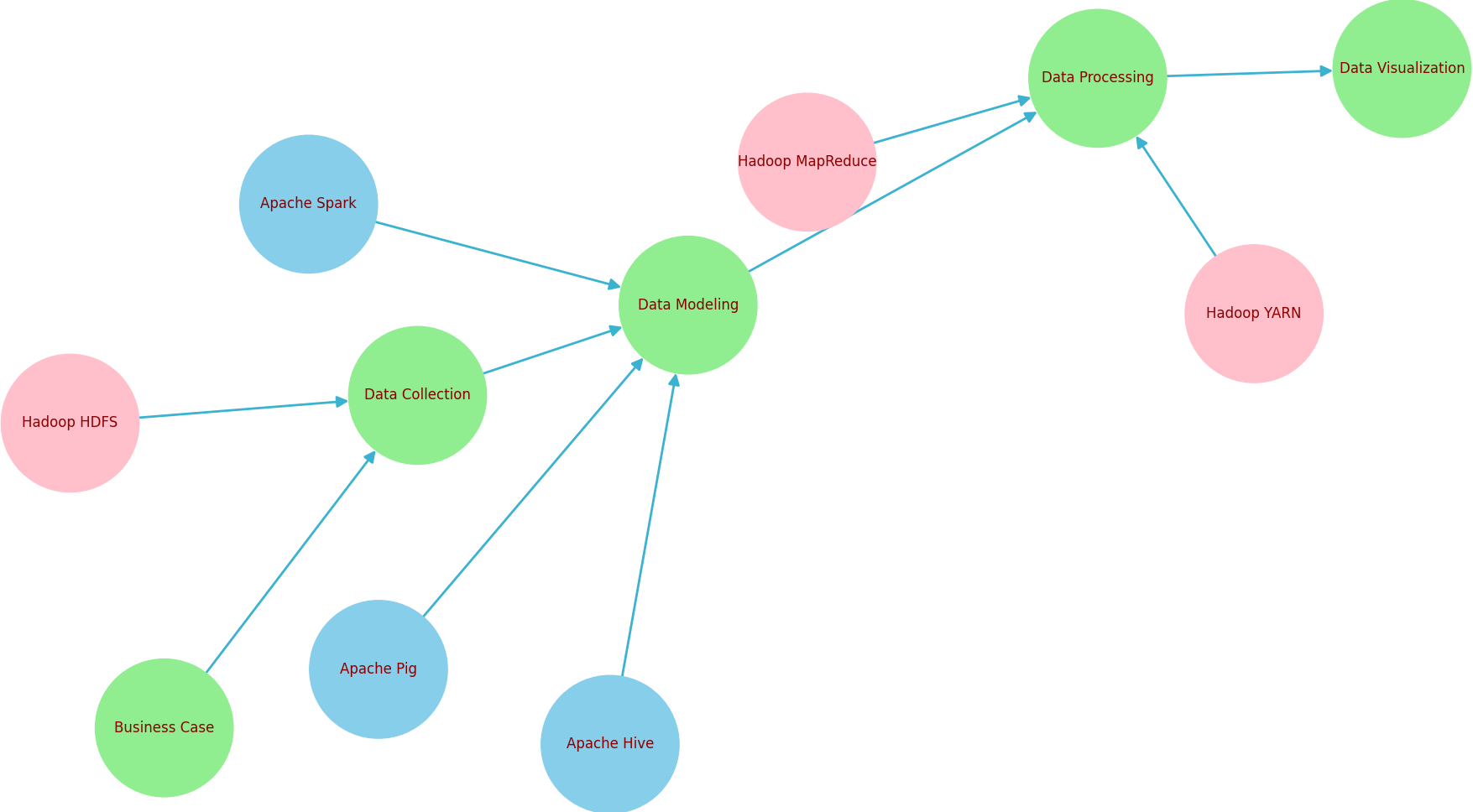
Figure 3403. Big data lifecycle (code).
As shown in Figure 3403, tools can be associated with different stages of the big data lifecycle based on their functions:
When discussing big data, the "four V's" often mentioned are Volume, Velocity, Variety, and Veracity. These four characteristics describe the challenges and opportunities that big data presents:
Volume: This refers to the sheer amount of data generated every second. In today's data-driven world, businesses and organizations generate vast quantities of data daily from various sources like social media, transactions, sensors, and more. Handling such large volumes of data requires specific technologies and architectures. - Velocity: This pertains to the speed at which data is generated, collected, and processed. High velocity means that data is being produced and refreshed at an extraordinary rate, necessitating real-time processing and analytics to derive value from it.
The primary attributes of velocity are:
Data Generation Speed: Velocity involves the rate at which data flows from various sources like IoT devices, online transactions, social media platforms, mobile devices, and more. High-velocity data requires systems that can process data in real-time or near-real-time to capture its value. - Real-Time Processing: Velocity implies the need for real-time processing capabilities to handle streaming data effectively. Technologies such as Apache Kafka, Apache Storm, and Apache Flink are designed to process and analyze data as it arrives, which is essential for applications that depend on timely decision-making.
- Data Refresh Rates: This refers to how frequently data updates occur. In environments where data changes rapidly, high velocity means continuous updates and possibly real-time synchronization across systems.
- Latency Requirements: Low latency is crucial in high-velocity data environments, where delays in processing can lead to missed opportunities or outdated insights. Reducing latency ensures that data processing and analysis are completed within a timeframe that maintains the data's relevance.
- Scalability: Systems handling high-velocity data must be scalable to accommodate sudden or continuous increases in data flow without degrading performance. Scalability in processing power and storage is essential to manage peak data loads efficiently.
- Data Pipeline Optimization: Efficient data pipelines are critical to manage high-velocity data. These pipelines must be optimized to handle the ingestion, transformation, and routing of data streams quickly and reliably.
- Timeliness of Data Insights: The value of data often diminishes over time. High velocity emphasizes the importance of deriving insights quickly to inform decisions that need to be timely, thereby improving operational effectiveness and competitive advantage.
- Variety: This describes the different types of data available, which can be structured, semi-structured, or unstructured. This diversity includes text, video, images, audio, and more, originating from multiple sources. The variety in data types often requires additional preprocessing to derive meaning and support analytics.
- Veracity: This involves the uncertainty of data, including biases, noise, and abnormalities in data. Veracity challenges the assurance of the accuracy and reliability of data, affecting decision-making processes.
===========================================
|

