|
||||||||
Practice Project of Data Processing Using Spark - Python Automation and Machine Learning for ICs - - An Online Book: Python Automation and Machine Learning for ICs by Yougui Liao - |
||||||||
| Python Automation and Machine Learning for ICs http://www.globalsino.com/ICs/ | ||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||
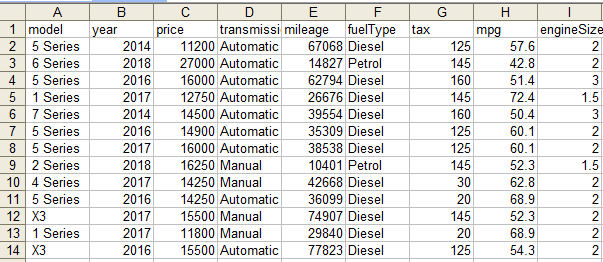
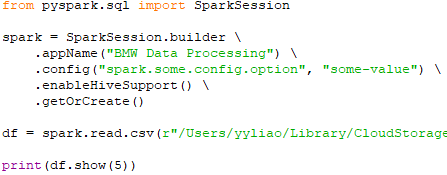
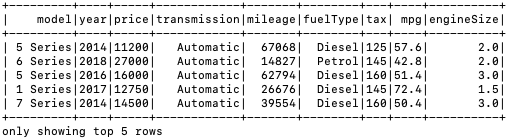
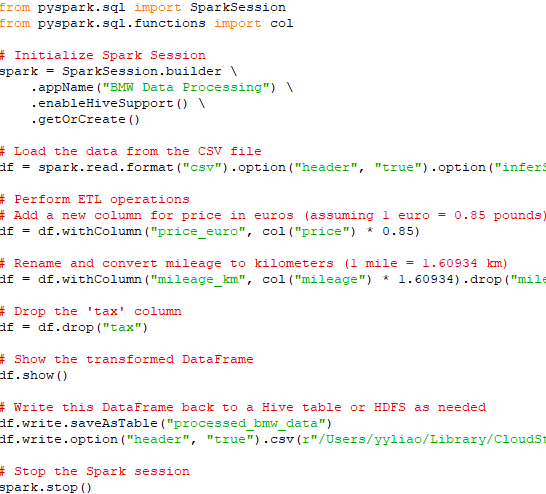
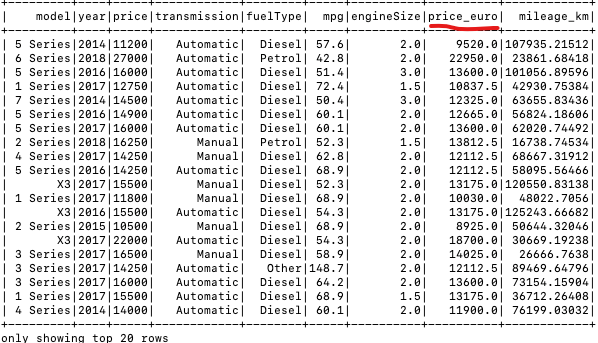
================================================================================= In the age of big data, the ability to efficiently process large volumes of information has become indispensable across industries. Apache Spark, renowned for its fast in-memory data processing capabilities, offers a versatile platform for handling complex data transformations and analysis at scale. Coupled with Hive, which provides a mechanism for managing and querying structured data in a distributed storage environment, this technology stack facilitates a sophisticated data processing pipeline that supports both batch and real-time processing needs. The scope of practice projects includes the acquisition of two distinct datasets, followed by a series of Extract, Transform, and Load (ETL) operations designed to integrate and refine the data for analytical purposes. Key tasks involve data cleansing, transformations such as adding and renaming columns, and the efficient handling of large-scale data joins. The culmination of these processes will see the transformed data being stored in a Hive warehouse and an HDFS file system, ensuring availability and accessibility for downstream analytics. Here’s a step-by-step guide to tackle the practice project:
===========================================
|
||||||||
| ================================================================================= | ||||||||
|
|
||||||||