=================================================================================
The combination of Mask R-CNN and YOLOv8 models can be highly beneficial in several areas within the semiconductor industry, particularly due to the industry's need for precision, speed, and automation. Here’s how these models can be applied across different semiconductor-related subjects:
- Defect Inspection and Quality Control
- Objective: Detecting and classifying defects on semiconductor wafers or in chip layouts.
- Application: YOLOv8 can rapidly identify areas with potential defects, and Mask R-CNN can then provide detailed segmentation of these defects, enabling precise identification and classification of various defect types such as cracks, contamination, and lithography errors.
- Photomask Manufacturing
- Objective: Inspecting photomasks used in lithography for imperfections or unwanted residues.
- Application: YOLOv8 can quickly scan photomasks for general anomalies, and Mask R-CNN can follow up with fine-grained analysis, precisely outlining and segmenting detected anomalies for further assessment and correction.
- Automated Optical Inspection (AOI)
- Objective: Enhance the automated optical inspection processes used in assembly lines.
- Application: Implement YOLOv8 for fast preliminary scanning of assembled circuits or components to spot inconsistencies, followed by detailed analysis with Mask R-CNN to determine the exact nature and severity of the detected issues.
- Process Monitoring and Control
- Objective: Monitor semiconductor manufacturing processes in real-time to detect deviations or anomalies.
- Application: Use YOLOv8 for continuous, real-time monitoring to quickly flag potential issues. Mask R-CNN can provide in-depth analysis of these issues, helping to ensure that the manufacturing process remains within specified tolerances.
- Wafer Dicing
- Objective: Ensure precise dicing of semiconductor wafers into individual chips.
- Application: YOLOv8 identifies the regions of interest on the wafer for cuts, and Mask R-CNN precisely segments the exact cutting lines, assisting in automated dicing systems to perform precise cuts that minimize waste and damage.
- Advanced Packaging
- Objective: Inspect and verify advanced packaging techniques like 3D IC packaging which involves stacking multiple silicon wafers and interconnecting them.
- Application: YOLOv8 can be utilized to ensure components are aligned correctly before packaging, while Mask R-CNN can meticulously check the integrity of the interconnects and other critical features post-packaging.
- Robotics and Automation in Manufacturing
- Objective: Enhance the capabilities of robotics used in the manufacturing and assembly of semiconductor devices.
- Application: Robots equipped with vision systems using YOLOv8 and Mask R-CNN can identify components, assess their positioning, and perform complex tasks such as assembly and soldering with high precision.
- Material Handling and Logistics
- Objective: Automate the logistics and material handling within semiconductor fabrication plants.
- Application: Use YOLOv8 for quick identification of materials and equipment, and Mask R-CNN for precise handling and placement tasks, ensuring that materials are correctly managed without human error.
In each of these applications, the combination of YOLOv8's speed and Mask R-CNN's accuracy provides a potent toolset for boosting efficiency, accuracy, and automation in the semiconductor industry, leading to cost savings and increased production capabilities.
For instance, in analyzing the nano-scratching process in TEM images, the decision to use both Mask R-CNN and YOLOv8 stems from the different strengths and capabilities of each model, which can complement each other to improve overall performance:
- Complementary Strengths:
- Mask R-CNN is highly effective at instance segmentation, which means it can accurately outline the exact shape and size of the scratches or the nano-scratching tool. This is crucial for tasks where precise spatial details are necessary, such as determining the boundaries of very small or closely spaced scratches. Configure Mask R-CNN to perform instance segmentation on the TEM images. This model will be crucial for understanding the precise morphology of scratches and the interaction area between the tool and the material.
- After initial detection, employ Mask R-CNN to provide detailed segmentation of the scratch and its impact on the material. This can help in closely analyzing the material deformation or failure mechanisms.
- YOLOv8, on the other hand, is renowned for its speed and efficiency in object detection, making it ideal for applications where real-time detection is critical. It can quickly process images to identify the presence and location of the nano-scratching tool and the initiation of scratches, although it may not provide as detailed segmentation as Mask R-CNN. Configure YOLOv8 for rapid detection of relevant objects, such as the nano-scratching tool or specific features of interest in the material before and after the scratch.
- Use YOLOv8 for the initial fast detection of the scratching tool and preliminary identification of the scratch area. This is useful for real-time monitoring and control during the scratching process.
- Robustness under Varying Conditions:
- Using both models could allow the system to be more robust under different imaging conditions. For example, Mask R-CNN might perform better in high-resolution images where detailed segmentation is possible, while YOLOv8 could be more reliable in scenarios where processing speed is prioritized or when images are less clear.
- Experimental Comparison:
- Including both models in the study could be part of an experimental setup to compare their effectiveness and determine which model or combination of models works best for the specific application of nano-scratching in TEM images.
- Error Reduction and Accuracy Improvement:
- By leveraging the strengths of both models, the system might reduce errors that could occur if relying on just one model. For instance, YOLOv8 could initially identify and localize the scratching tool or the scratch quickly, and then Mask R-CNN could follow up with precise segmentation to refine the results and analyze the material deformations.
- Hybrid Approaches:
- The researchers might be exploring a hybrid approach that integrates the outputs of both models to enhance overall accuracy and reliability. This could involve using YOLOv8 for initial detections and Mask R-CNN for detailed analysis, or vice versa, depending on the specific needs and constraints of the application.
- Deployment and Real-Time Use
- Real-Time Application: Implement the models in a real-time setting where YOLOv8 could control the scratching tool by quick detections, and Mask R-CNN could perform post-scratch analysis to evaluate the material properties and scratch quality.
- Feedback Loop: Consider establishing a feedback mechanism where the outcomes from the Mask R-CNN could feedback into the operational parameters to adjust the scratching process dynamically.
Mmetrics such as precision, recall, IoU (Intersection over Union), and processing time can be used to evaluate both Mask R-CNN and YOLOv8 models.
In a deep learning project such as the one involving in-situ TEM for nano-scratching using models like Mask R-CNN and YOLOv8, different components of the neural network architectures play specific roles in processing the input data (images) to produce the desired output (detections and segmentations): - Input Layer
- Function: This layer takes the raw input data, which in your case would be the TEM images. It formats these images into a consistent shape and size that the network can process, usually as fixed-size tensors or matrices of pixel values.
- Purpose: Ensures that the network receives input in a uniform manner, facilitating efficient processing in subsequent layers.
- Feature Extraction Layer
- Function: These layers, typically made up of convolutional layers, are responsible for detecting various features in the images. They do this by applying filters (or kernels) that capture specific types of visual features such as edges, textures, or patterns at different scales and orientations.
- Purpose: To abstract and compress raw image data into a form where salient features are highlighted and easier for the network to interpret in further layers.
- Encoder
- Function: In architectures that have an explicit encoder (common in autoencoders or certain types of RNNs), this component further processes the features extracted by initial layers to create a condensed representation of the input data.
- Purpose: To reduce the dimensionality of the feature space, capturing the most critical aspects of the input data in fewer dimensions, which can be especially useful in segmentation and anomaly detection.
- Attention Mechanism
- Function: Although not typically a part of basic CNN architectures like YOLO or Mask R-CNN, an attention mechanism can selectively focus on parts of the input data that are more relevant for the task, improving the model's ability to recognize complex features in large or cluttered images.
- Purpose: To enhance model performance by weighting the importance of different features in the data, often leading to better handling of input data variability and improving outcomes in tasks requiring fine detail recognition.
- Decoder
- Function: In models that involve segmentation or data reconstruction, the decoder gradually reconstructs the target output from the encoded features. In segmentation tasks, like with Mask R-CNN, the decoder part reconstructs the segmentation masks from the condensed feature representations.
- Purpose: To translate the high-level, abstracted features back into a detailed output that matches the desired format, such as a detailed pixel-wise mask in segmentation tasks.
- Output Layer
- Function: This is the final layer in the network that formats the outputs of the neural network into a usable form, such as bounding boxes and class labels in detection tasks or pixel-wise masks in segmentation tasks.
- Purpose: To convert the processed features into concrete predictions that can be easily interpreted and used for practical applications. In YOLOv8, this would include the coordinates of bounding boxes and class probabilities; in Mask R-CNN, it includes not only the bounding boxes but also the segmentation masks.
- Additional Layers
- Includes normalization layers (like Batch Normalization), activation functions (like ReLU), and pooling layers (like Max Pooling) which are essential for training deep neural networks effectively.
Figure 3281 shows the Neural Network Architecture for TEM nano-scratching analysis.
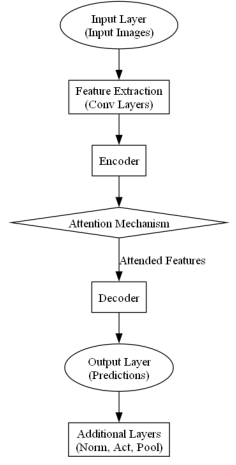
Figure 3281. Neural Network Architecture for TEM nano-scratching analysis (code).
===========================================
|
