=================================================================================
Features that are constant (i.e., have the same value across all data points) or quasi-constant (i.e., vary very little and are almost constant) generally do not contribute meaningful information for predictive modeling or data analysis. They do not help in distinguishing between different observations and typically don't influence the output of predictive models. Here are a few reasons why they're often considered noise: - No Variability: Features with little or no variability cannot improve model performance because they don't help in splitting the data in a meaningful way during the training of models such as decision trees.
- Redundant Information: They add no additional information that could be used by the model to learn patterns from the data.
- Efficiency: Removing such features can help in reducing the dimensionality of the data, which in turn can lead to less complex models, faster training times, and sometimes improved model performance due to the reduction of noise.
- Stability: In some cases, a quasi-constant feature might appear non-constant due to minor variations like measurement errors; relying on such features can potentially lead to less stable model performance.
However, it's important to assess the relevance of any feature in context. In some rare cases, a feature that appears constant or quasi-constant could carry some important information depending on the specific domain or problem.
In feature selection for machine learning, removing unnecessary features such as constant and quasi-constant, or low-variance features can help improve the performance and interpretability of your model:
- Removing Constant Features
Constant features are those that have the same value for all observations. These features do not provide any useful information for predictive modeling. Code: 
Output:

In this output, the constant features (columns) are dropped.
- Removing Quasi-Constant or Low Variance Features
Quasi-constant features have the same value for a large majority of the observations, with a small variance. These features have little variation in their values. Although not as extreme as constant features, they also contribute minimally to the predictive power of the model. Removing low variance features can help simplify the model and potentially improve its performance. Therefore, these features also provide limited information. In this case, we can set a threshold to identify quasi-constant features. For example, if a feature has the same value for 99% of the observations, you might consider it quasi-constant. Code: 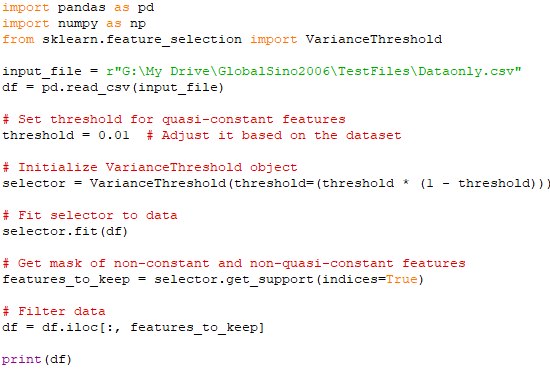
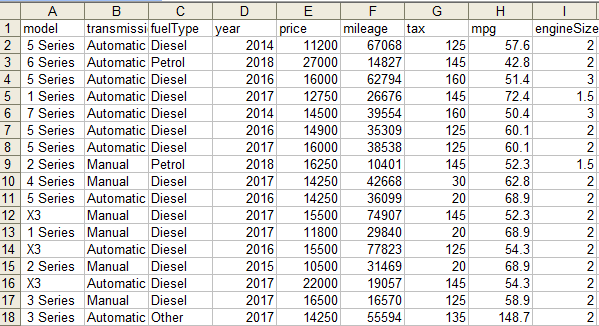
Input: 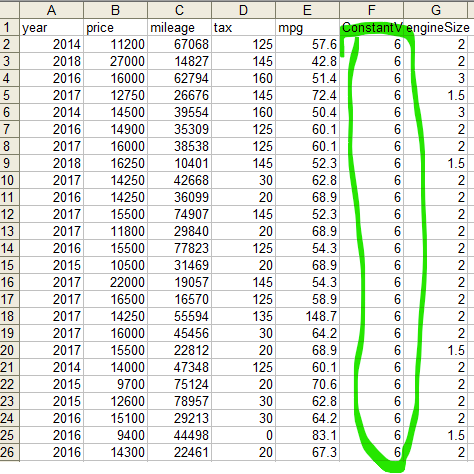
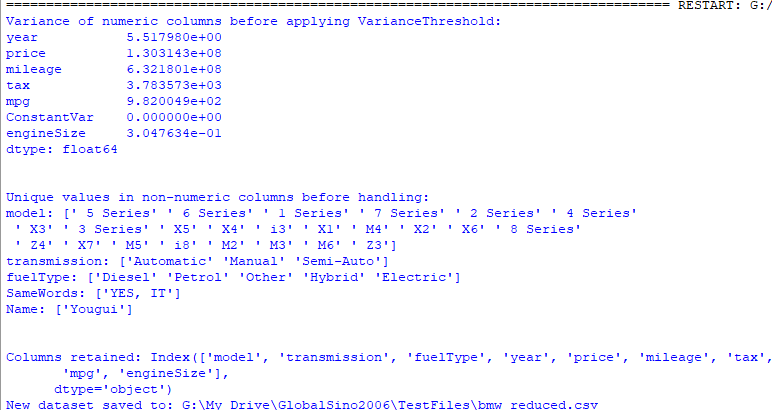
Output: 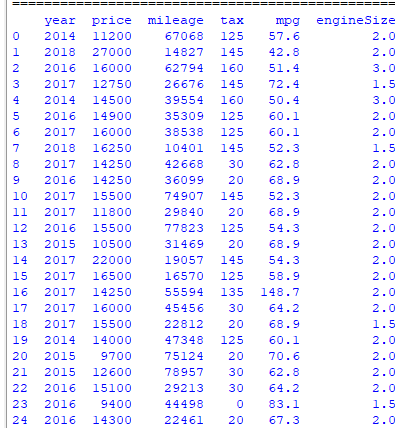
In this code above, df.select_dtypes(include=[pd.np.number]) is used to select only the numeric columns from the DataFrame, and VarianceThreshold is applied to the resulting numeric DataFrame since VarianceThreshold . This removes all features whose variance does not meet the threshold. The threshold is set to a small number (e.g., 0.01), meaning if a feature has the same value in at least 99% of the observations, it will be removed. The get_support method returns an array of indices of the columns that are kept. In this output, the column "ConstantV" in the input dataset has been removed since the column only contains constants. This is a technique used to automatically remove features with variance below a certain threshold. It is part of the preprocessing step in building a machine learning model.
Overall, this process will help us clean our dataset by removing features that do not contribute significantly to the predictive power of our model. However, this code above cannot handle the situations where non-numeric columns presents in the DataFrame.
- Complex removal of
unnecessary features
(Code)
In complex cases, besides numeric columns, we also need to either drop these non-numeric columns or convert them to numeric values if possible. Namely, the numeric and non-numeric columns are handled separately. Note that the columns containing strings are categorical columns. NumPy and df.select_dtypes(include=[pd.np.number]) are used to select only the numeric columns from the DataFrame, and VarianceThreshold is applied to the resulting numeric DataFrame since VarianceThreshold only works with numeric data. Here, non-numeric columns are checked for constant values, and those columns are dropped if they have the same value across all rows. Finally, the remaining numeric and non-numeric columns are concatenated back together. Input:
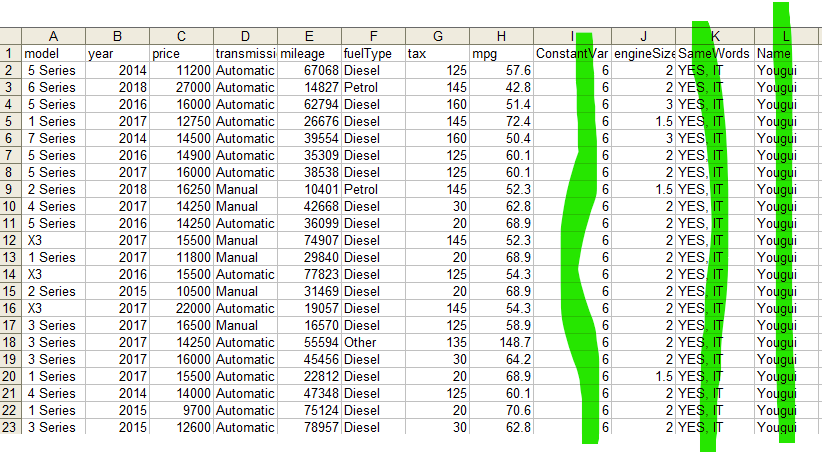
Output:
===========================================
|
