=================================================================================
Univariate feature selection is a technique used in machine learning and statistics to select the most relevant features (variables) for use in model building. This method involves evaluating each feature individually to determine its relationship with the target variable. The key aspects of univariate feature selection are:
- Relevance Evaluation: Each feature is assessed independently to determine its relevance to the target variable. Common metrics used for this evaluation include statistical tests like chi-square, ANOVA F-test, and mutual information.
- Statistical Tests:
- Chi-Square Test: Used for categorical features, it tests whether there is a significant association between the feature and the target variable.
- ANOVA F-Test: Used for continuous features, it tests whether the means of different groups (based on the feature) are significantly different.
- Mutual Information: Measures the amount of information gained about the target variable by knowing the feature.
- Selection Criteria: Features are ranked based on their scores from the statistical tests. A threshold is set, and features with scores above the threshold are selected for model building. Alternatively, a fixed number of top-ranked features can be chosen.
- Independence Assumption: This method assumes that features are independent of each other, which might not always be true in practice. Despite this limitation, univariate feature selection is a simple and effective method for reducing dimensionality and improving model performance.
- Implementation: In practice, libraries like Scikit-learn in Python provide built-in functions for univariate feature selection, such as SelectKBest and SelectPercentile.
In general, univariate feature selection helps in simplifying models, reducing overfitting, and improving model interpretability by selecting the most significant features related to the target variable. This script performs univariate feature selection on the dataset below.
Input data:
Output:
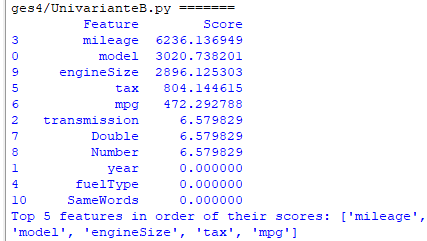
The script uses the SelectKBest method from Scikit-learn to select the best features based on the ANOVA F-test for regression problems. This script does:
- Encodes categorical variables using LabelEncoder.
- Defines the features (X) and the target variable (y).
- Uses SelectKBest with the ANOVA F-test to score the features.
- Selects the top k features based on the scores.
- In univariate feature selection, we need to separate the features from the target variable to evaluate the importance of each feature in predicting the target variable. Two columns "price" refer to different roles in the feature selection process:
- X = df.drop(columns=['price']): This line defines the feature matrix X by dropping the "price" column from the dataframe. X contains all the features (independent variables) used to predict the target variable.
- y = df['price']: This line defines the target variable y as the "price" column. y contains the values that we want to predict using the features in X.
===========================================
|
